目录
One stageFCOSSSDSingle shot detection, SSDDSSDFSSDRefineDetRetinaNetYOLOYOLO V1YOLO V2 & YOLO9000YOLOV2YOLO9000YOLO V3YOLO V4YOLO V5Two stageFaster RCNNMask RCNNFeature pyramid network,Resnet structureResnet-FPN+Fast RCNNResnet-FPN+Fast RCNN+MaskROI AlignLoss definitionCascade RCNNCoupleNetObject trackingROLOSiamMaskDeep SORTTrackR-CNNTracktorJDEAppendix
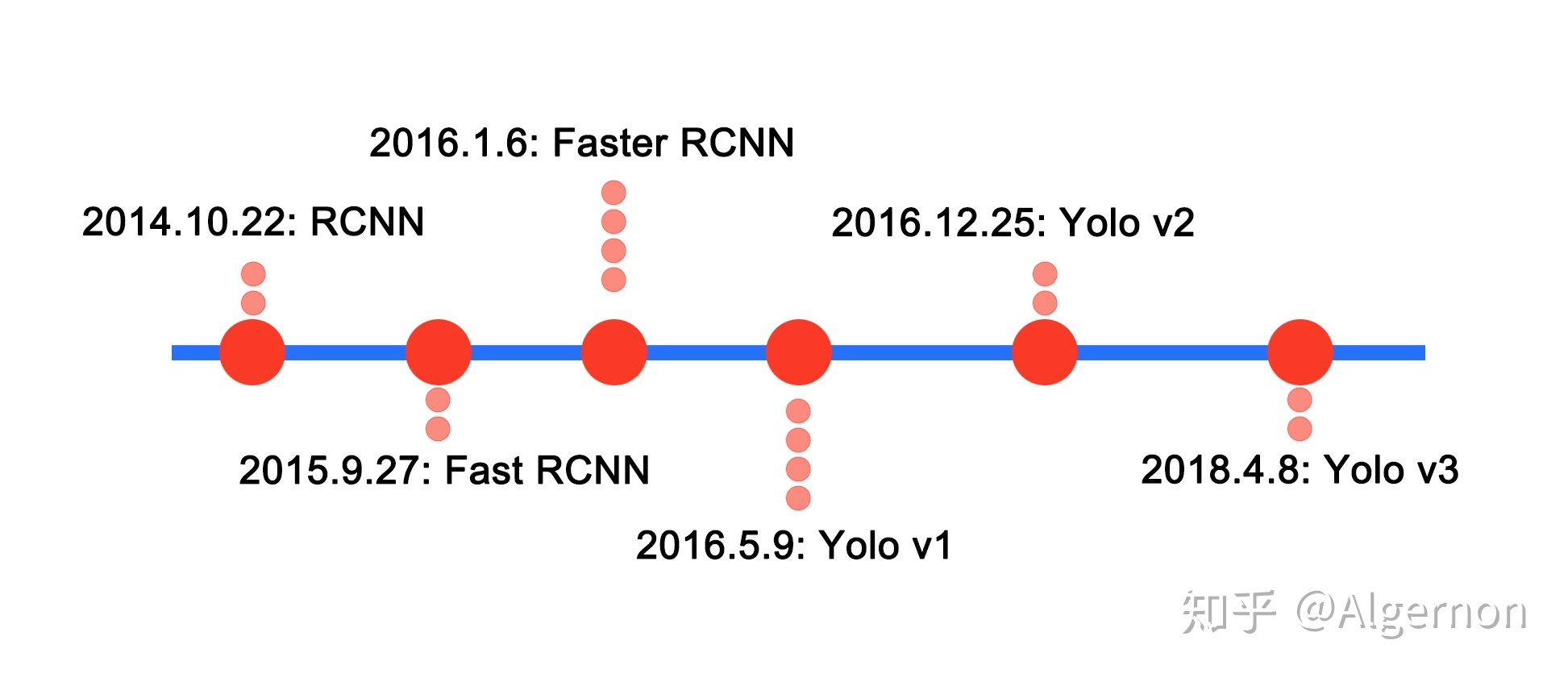
YOLOv4已经可以达到和faster rcnn基本一致的准确率,但速度提升了5倍
检测算法优化的目标在于:寻求检测速度与精度的平衡
One stage
FCOS
核心思想:预测输入图像中每个点所属的目标类别和目标框,回归支路是核心。

输入图像上每个点的类别标签就可以根据这个点是否在标注框内来确定,在标注框外的点就是负样本,类别设置为0;在标注框内的点(x,y)就是正样本,类别目标就是标注框的类别。
因此可以看出FCOS的正负样本是基于每个点的,一般一张图像上目标框的面积和非目标框的面积差距不会非常大,因此基本不存在正负样本不均衡的现象。
图像中存在2个部分重叠的标注框,那么2个目标框重合部分的点的训练目标该怎么算?
因为目标框重合是比较常见的现象,因此这个问题就显得十分重要,作者也通过实验证明了这样的歧义样本(ambiguous sample)大概占23.16%.
为了解决这个问题,作者引入FPN结构并基于不同特征层预测不同尺度的目标框,这样就将大部分有重合的目标框剥离开来,在不同特征层分别预测,而区分哪些点在哪个特征层预测的依据是该点的(l, t, r, b)这4个值的最大值是否在预先设定好的范围内。当然,这种区分主要也是基于大部分有重合的目标框尺度差别较大,假如重合目标框大小接近且类别不同,那还是比较棘手的。
基于这样的优化,这种歧义样本数量就降到7.14%,再进一步,假如歧义样本所属的框类别一样,那这种情况对回归来说影响相对小一些,假如把这样的歧义样本去掉,那么比重就进一步降低至3,75%,可以看到影响越来越小。作者也通过实验证明引入FPN且为每个特征层分配不同尺度的目标框对最终检测指标的影响,基本上差了一倍。
SSD
Single shot detection, SSD
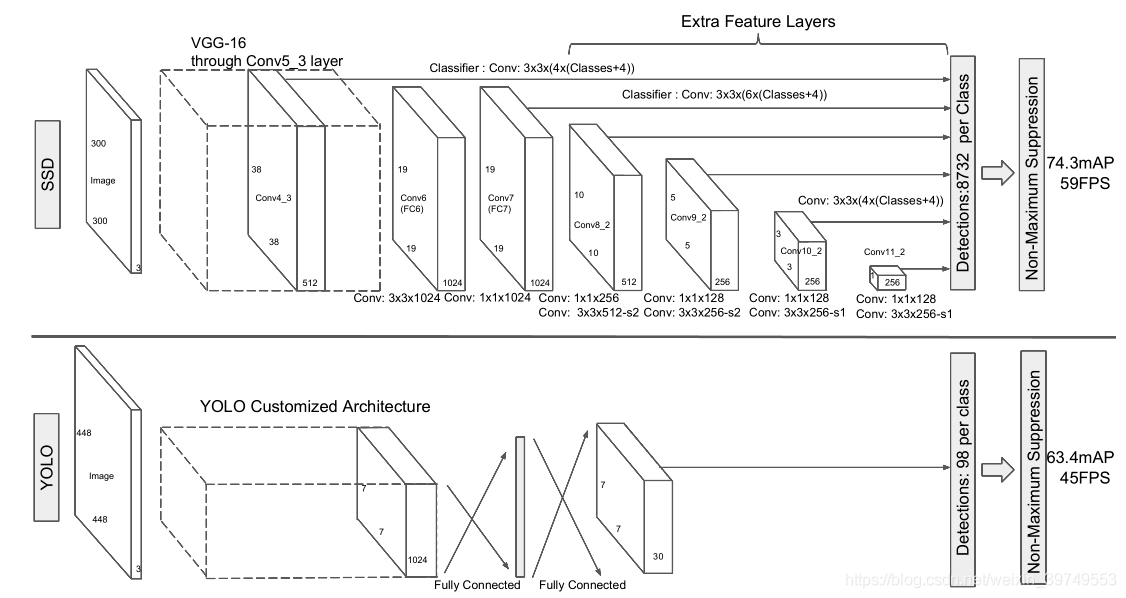
在图中,我们可以大概看下模型的结构,前半部分是vgg-16的架构,作者在vgg-16的层次上,将vgg-16后边两层的全连接层(fc6,fc7)变换为了卷积层,conv7之后的层则是作者自己添加的识别层。
使用一层(3,3,(4*(Classes+4)))卷积进行卷积(Classes是识别的物体的种类数,代表的是每一个物体的得分,4为x,y,w,h坐标,乘号前边的4为default box的数量),不仅在conv4_3这有一层卷积,在Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2都有一层这样的卷积层,因此最后提取到6个feature map层。
最后的Detections,8732 per Class:
- Conv4_3 的feature map大小为38*38得到bbox数量:38*38*4 = 5776
- Conv7 的feature map大小为19*19得到bbox数量:19*19*6 = 2166
- Conv8_2 的feature map大小为10*10得到bbox数量:10*10*6 = 600
- Conv9_2 的feature map大小为5 * 5得到bbox数量 :5 * 5 * 6 = 150
- Conv10_2的feature map大小为3 * 3 得到bbox数量:3 * 3 * 4 = 36
- Conv11_2的feature map大小为1 * 1 得到bbox数量:1 * 1 * 4 = 4
其中,4或6是default box的数量,根据定义的公式(feature map层级,大小,长宽等)计算bbox在原图的尺寸
- 4 box:(1:1), (2:1), (1:2), (1:1)
- 6 box:(1:1), (2:1), (1:2), (1:1), (1:3), (3:1)
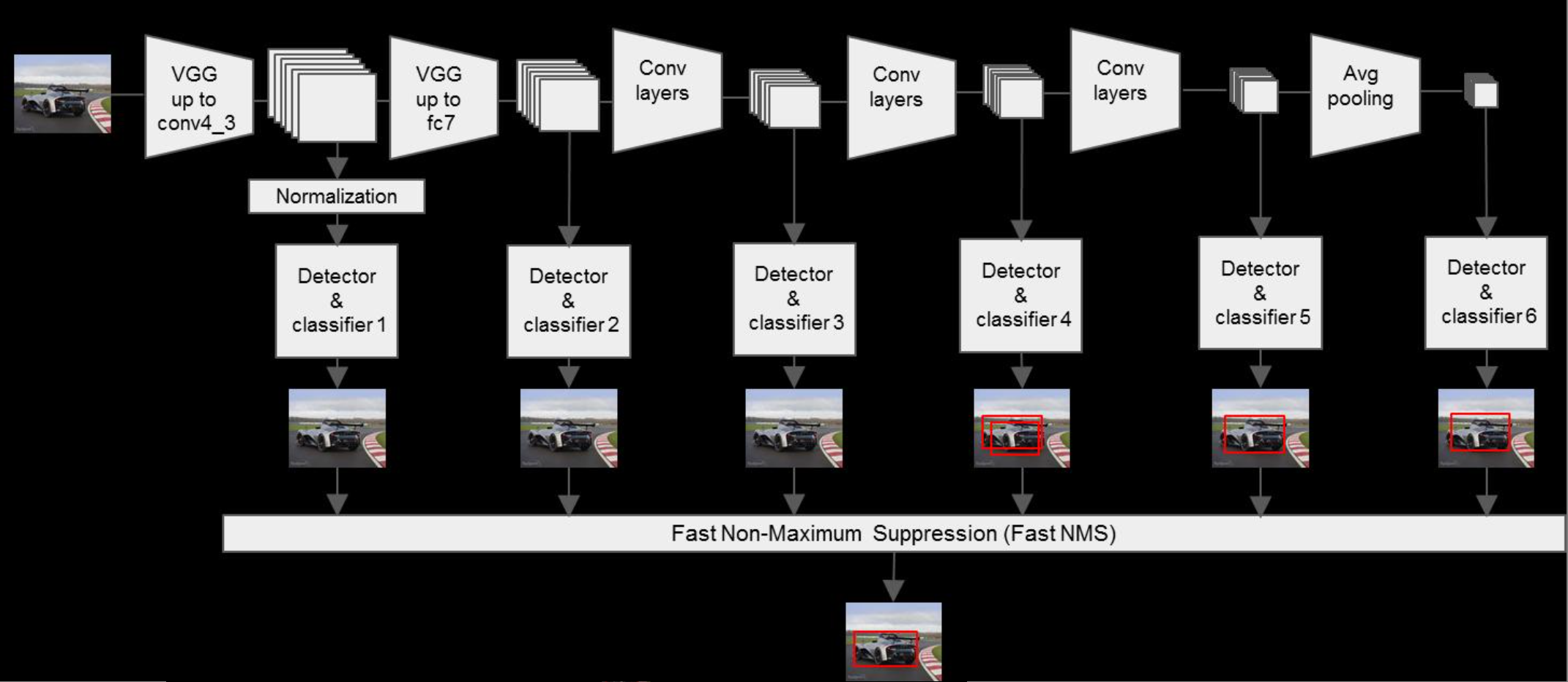
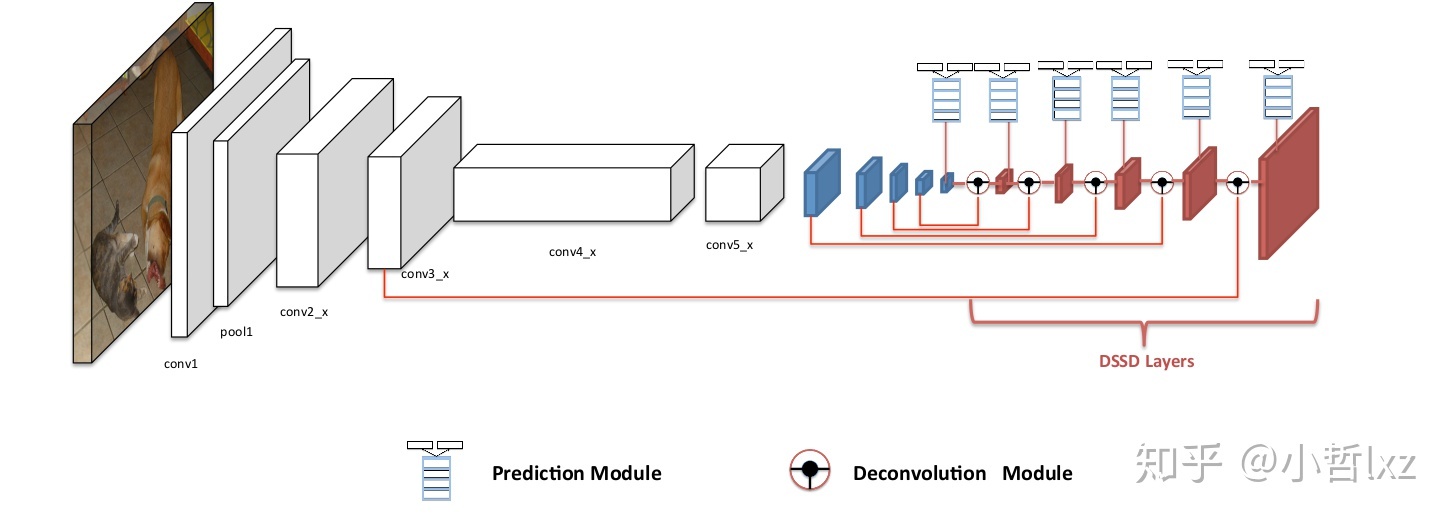
DSSD
DSSD算法着眼于ssd对于小目标物体的检测效果依然不够理想,分析原因,就是浅层的特征图虽然比较容易定位小目标,但是浅层的特征图没有包含充分的语义信息,很难对定位出的目标进行分类。
因而,利用反卷积将特征图进行上采样,与原始的特征图进行融合,然后混合后的特征图输入感知器网络进行预测(感知器网络就是几层卷积层,输出为特定的维度,维度与位置与类别有关)。
将原始特征图与上采样后的特征图进行融合的方法一般有堆叠(concat)与求和(element-wise sum),但是这里作者经过实验说明在这种结构下(element-wise product)矩阵点积的效果比element-wise sum更好。
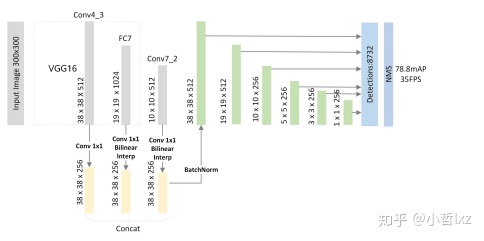
FSSD
同样考虑到ssd算法独立的利用浅层与深层的特征图进行预测,对小物体的鲁棒性较差,提出了一种特征融合的方式,将vgg16产生的不同尺度的特征图,利用双线性插值变换为conv4-3层的特征图尺度大小,然后concat所有特征图,利用得到的特征图重新进行下采样得到不同的特征图尺度,输入感知器网络进行预测。
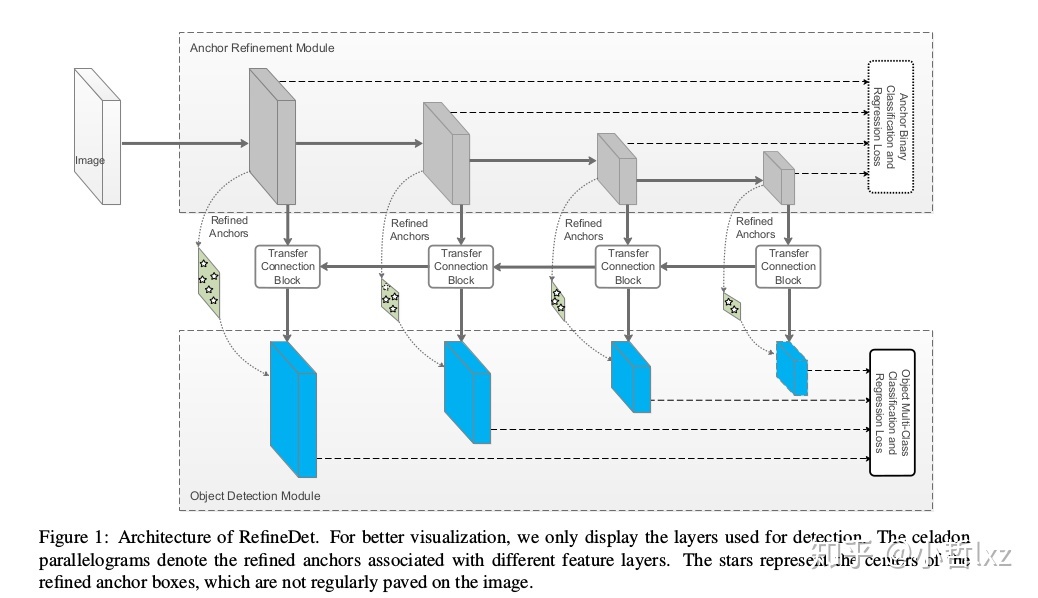
RefineDet
此算法对于ssd的修改最多,而且这中算法看起来好像是目标检测一步法与两步法的结合算法。
整体来看该网络和tow stage的结构很像(都可以概括为two-step cascaded regression),一个子模块(anchor refinement module (ARM))对先验框进行二分类与回归,类似于RPN的功能,另一个子模块类似于SSD(object detection module (ODM))。在RefineDet中是先通过ARM部分生成refined anchor boxes(类似RPN网络输出的propsoal),然后在refined anchor boxes基础上进行回归,所以能有更高的准确率.
RetinaNet
Coming soon.
YOLO
one stage的检测算法,难点在于数据拟合到极限之后,类别正确率、识别准确率、识别召回率、检测框精度之间的权衡。
对大分辨率图片先进行分割,变成一张张小图,再进行检测。
yolov2, anchor box如何与loss结合,dimension cluster,bbox使用kmeans聚类获得,距离函数为1-IOU,获得k个中心点
关于one stage方法中,anchor的个人理解:理解为根据网络结构以及输出的尺寸,人为的给出关于anchor的解释,其实主要依靠的是label的设计,主要是label设计与anchor解释的结合,说到底还是回归/拟合问题,暴力求解
工程上,大部分时间在于如何根据规则,根据每个bbox的大小与位置,生成对应的groundtruth label,并验证正确性。
YOLO V1
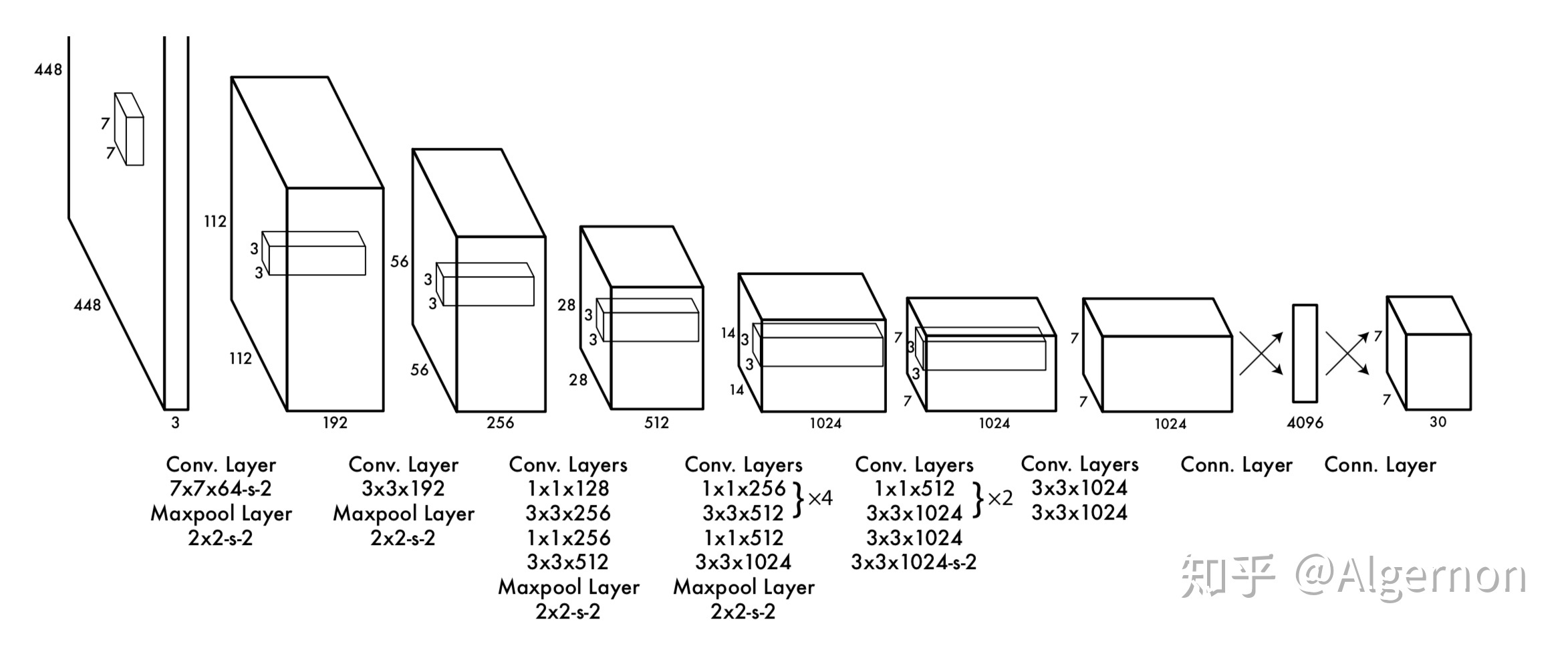
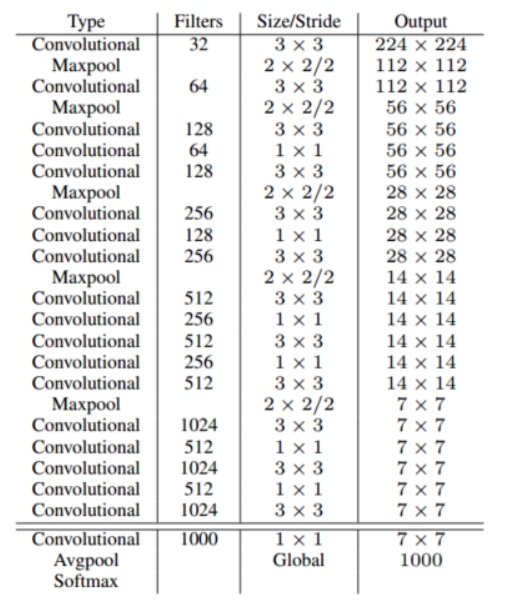
Yolo的backbone网络结构,受启发于GoogLeNet,也是v2、v3中Darknet的先锋。本质上来说没有什么特别
- 没有使用BN层,用了一层Dropout
- 除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。
网络结构:

输出7*7
如果一个物体的中心点,落在了某个格子中,那么这个格子将负责预测这个物体。
dimension: 30
在Yolo v1论文中,30是由(4+1)*2+20, 20代表预测20个类别。其中4+1是矩形框的中心点坐标x,y,长度w,h以及被检测物体的置信度c; 2代表一个格子共回归两个矩形框;20代表预测20个类别。那么每个方格只产生两个矩形框,最后选定置信度更大的矩形框作为输出,也就是最终每个方格只输出一个预测矩形框。
tricks:
11. offset代替坐标22. 每个格点预测两个框,loss function中,只对c更大的框计算与真实框的损失;这样操作之后,作者发现,一个格点的两个框,在尺寸、长宽比或者某些类别上逐渐有所分工,总体召回率有所提升33. 使用nms非极大值抑制生成预测框44. 推理时,将confidence\*cls_prob作为预测物体的置信度
YOLO V2 & YOLO9000
Yolov2和Yolo9000算法内核相同,区别是训练方式不同:Yolov2用coco数据集训练后,可以识别80个种类。而Yolo9000可以使用coco数据集 + ImageNet数据集联合训练,可以识别9000多个种类。
YOLOV2
tricks:
- backbone: 提出了Darknet-19 vs. VGG-16
- 引入BN,去除dense layer和dropout
- 输入分辨率增大,现在imagenet上预训练,再在coco上微调
- 不对矩形框的宽高的绝对值进行预测,而是预测与anchor框的偏差;每个格点指定n个anchor框;在训练时,最接近ground truth的框产生loss,其余框不产生loss。引入anchor之后,mAP下降,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降
- anchor box的选取:将训练集矩形框使用kmeans聚类得到五个先验框的宽prior_w和高prior_h, yolo预测
- pass through层/focus&slice, 横纵每间隔一个pixel,1 channel转换为4channel,相比pool layer保留更多的细粒度特征
- 多尺度训练,32的倍数
YOLO9000
tricks:
- Joint classification and detection:当输入图片只包含分类信息是,loss只计算分类loss,其余loss为零;
- 训练策略:现在检测数据集上训练一定的epoch,待预测框loss稳定后,在联合分类数据集、检测数据集进行交替训练;同时为了分类、检测数据量平衡,对coc数据集进行了采样,是的coco物体框总数与ImageNet大致相同
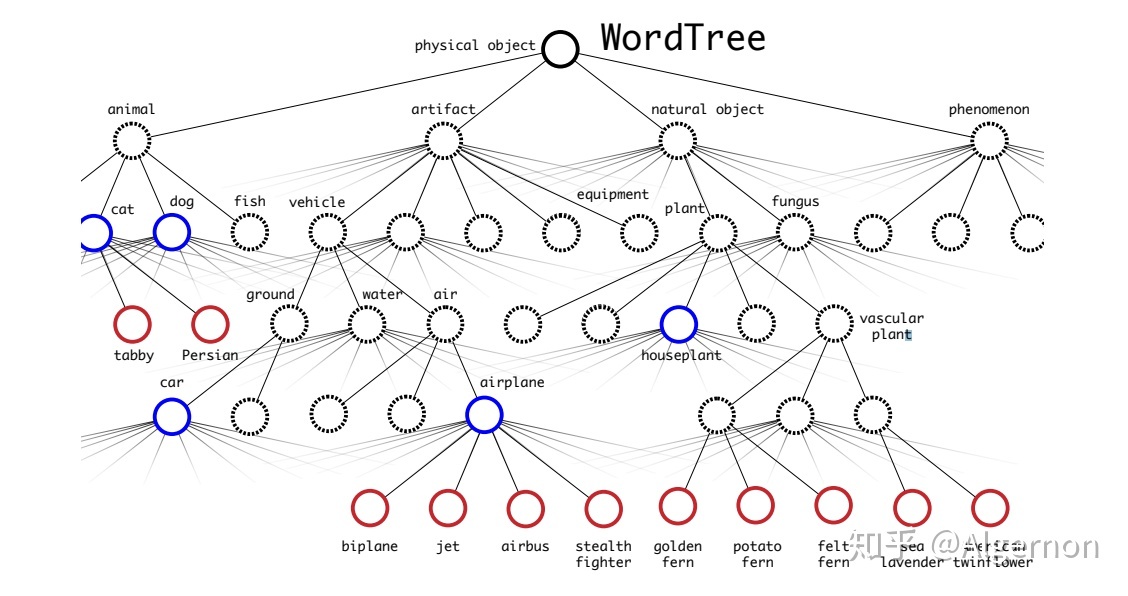
- Dataset combination with WordTree:使用wordtree,树结构表示物体之间的从属关系,第一大类,下分不同层级,同一大类中只有一个类别预测分值最大。预测时,从根节点开始向下检索,每次选取预测分值最高的子节点,直到所有选择的节点预测分值连乘后小于某一阈值时停止。训练时,如果标签为人,那么只对人这个节点以及其所有父节点进行loss计算。
YOLO V3

借鉴金字塔特征图,小尺寸特征图用于检测大尺寸物体,大尺寸特征图检测小尺寸物体,三层金字塔,每层金字塔对应9/3=3个anchor box,吸取了Resnet、Densenet、FPN的精髓
tricks:
backbone:darknet-53
只有卷积层,通过调节卷积步长控制输出特征图尺寸
借鉴金字塔特征图的思想,小尺寸特征图用于检测大尺寸物体
输出维度:
concat操作:来源于densenet网络的思想,将特征图按通道维度直接进行拼接
loss function策略很重要:
预测框分三种情况:
- 正例 positive:任取一个groundtruth,与所有预测框计算IOU,IOU最大的框即为正例(不需要大于阈值);并且一个预测框,只能分配给一个ground truth;正例产生confidence loss、detection loss、classification loss
- 忽略 ignore:任意一个groundtruth的IOU大于阈值,但不是最大值(即不是正例),为忽略样例,忽略样例不产生任何loss
- 负例 negative:与全部groundtruth的IOU均小于阈值,则为负例;负例只有confidence loss,ground truth label为0
loss函数:
- loss为三个特征图之和
- 每层的loss定义为:
- 其中
- x, y, w, h使用MSE作为损失函数,也可以使用smooth L1 loss(源自faster rcnn)作为损失函数;smooth L1可以使训练更加平滑
- confidence loss、classification loss都是01分类,使用交叉熵作为损失函数
- loss为三个特征图之和
相比yolov1:
groundtruth不是按照中心落在grid cell中来分配,因为将所有预测的bbox分在三个特征金字塔中,无法准确确定一个groundtruth所述哪个金字塔,因此采用集合所有预测的bbox,根据IOU来区分正例负例;其实该方法与faster rcnn已经很像了,即先遍历获得大量的candidate bbox,再selective search其中每个与groundtruth最接近的样本来计算loss,获得预测结果,已经和原本yolov1的设计与数据集构造理念不同。
yolov1中,预测框置信值标签为IOU;yolov3中,置信值为1
- 通过实验发现,预测框与真实框的IOU极限值为0.7左右,导致置信度学习有一些偏差,最后学到0.5,0.6;预测时容易有更多框被过滤掉。所以yolov1中,置信度的标签始终很小,无法有效学习,导致检测召回率不高,而yolov3中,召回率明显提升了很多
忽略样例的作用:
- yolov3的画龙点睛之笔;由于多尺度特征图,不同尺度的特征图之间会有重合检测部分;比如两个不同特征图中,iou分别为0.98和0.95,如果强行给0.95打0的标签,会导致学习效果不理想;即最终的loss会变成
- yolov3的画龙点睛之笔;由于多尺度特征图,不同尺度的特征图之间会有重合检测部分;比如两个不同特征图中,iou分别为0.98和0.95,如果强行给0.95打0的标签,会导致学习效果不理想;即最终的loss会变成
YOLO V4
对各个子结构修改,引入新结构,实现了精度和速度的最佳平衡
主要贡献点:
- 开发了一个高效而强大的模型,可训练获得一个快速精确的目标检测器
- 验证了一系列state of the art的目标检测器训练方法的影响,分为BoF和BoS两大类,比如修改backbone、neck、head网络模块,loss设计、数据增强
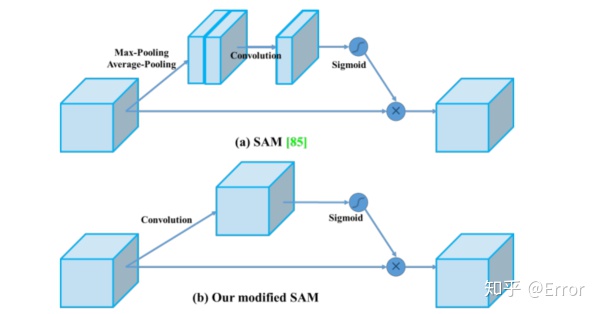
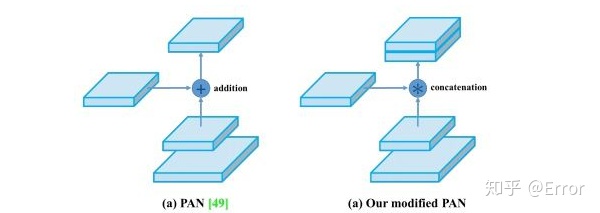
- 修改了state of the art方法,使得他们在使用单个GPU进行训练是更加有效和适配,包括CBM、PAN、SAM
目标检测常见架构:
Input部分:Image,Patches,Images Pyramid(图像金字塔)
Backbone部分:VGG16,ResNet-50,SpineNet,EfficientNet-B0 / B7,CSPResNeXt50,CSPDarknet53
neck部分:
- Additional blocks:SPP,ASPP,RFB,SAM
- Path-aggregation blocks:FPN,PAN,NAS-FPN,Fully-connected FPN,BiFPN,ASFF,SFAM
Heads部分:
Dense Predictions(one-stage):
- RPN,SSD,YOLO,RetinaNet (基于anchor)
- CornerNet,CenterNet,MatrixNet,FCOS(无anchor)
Sparse Predictions(two-stages):
- Faster R-CNN,R-FCN,Mask R-CNN(基于anchor)
- RepPoints(无anchor)

作者把训练的方法分成了两类:
Bag of freebies:只改变训练策略或者只增加训练成本,比如数据增强。
- 比如数据增广的方法:图像几何变换、Cutout、grid mask等,
- 数据增强:CutMix、Mosaic
- 网络正则化的方法:Dropout、Dropblock每个特征图随机的cutout模糊处理(125,125,125)等,
- 类别不平衡的处理方法,
- 难例挖掘方法,
- 损失函数的设计等,
Bag of specials:插件模块和后处理方法,它们仅仅增加一点推理成本,但是可以极大地提升目标检测的精度。
- 比如增大模型感受野的SPP、ASPP、RFB等,
- 引入注意力机制Squeeze-and-Excitation (SE) 、Spatial Attention Module (SAM)等 ,
- 特征集成方法SFAM , ASFF , BiFPN等,
- 改进的激活函数Swish、Mish等,
- 或者是后处理方法如soft NMS、DIoU NMS、GIOU NMS等
在目标检测训练中,通常对CNN的优化改进方法:
- 激活函数:ReLU,leaky-ReLU,parameter-ReLU,ReLU6,SELU,Swish或Mish
- bbox回归loss函数:MSE,IoU,GIoU,CIoU,DIoU
- 数据增强:CutOut,MixUp,CutMix
- 正则化方法:DropOut,DropPath,Spatial DropOut或DropBlock
- 通过均值和方差对网络激活进行归一化:Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), orCross-Iteration Batch Normalization (CBN)
- 跨连接:Residual connections, Weightedresidual connections, Multi-input weighted residualconnections, or Cross stage partial connections (CSP)
YOLO V5
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。Yolov5代码中给出的网络文件是yaml格式,和原本Yolov3、Yolov4中的cfg不同。
Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。

数据预处理:
- Mosaic数据增强
- 自适应锚框计算
- 自适应图片缩放,宽高等比例缩放后填充至要求尺寸
高分辨率小目标检测时,先将整张图切分,分别预测结果后整合bbox,overlap去除等。
集大家之所长,取长补短。结合各种trick,暴力寻找最佳model。
Two stage
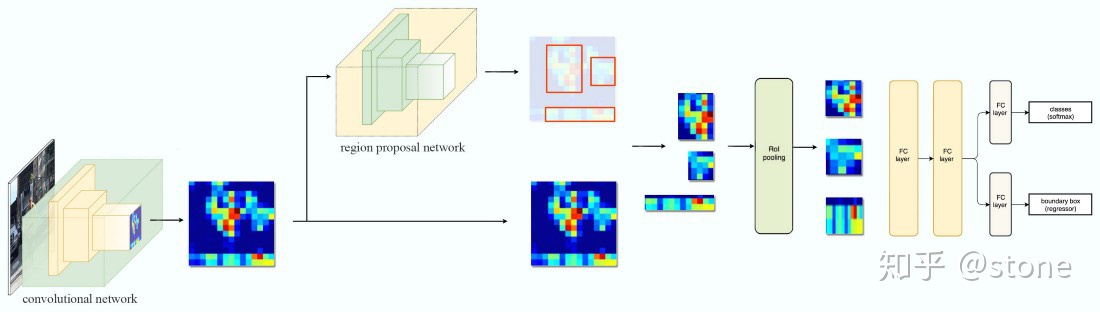
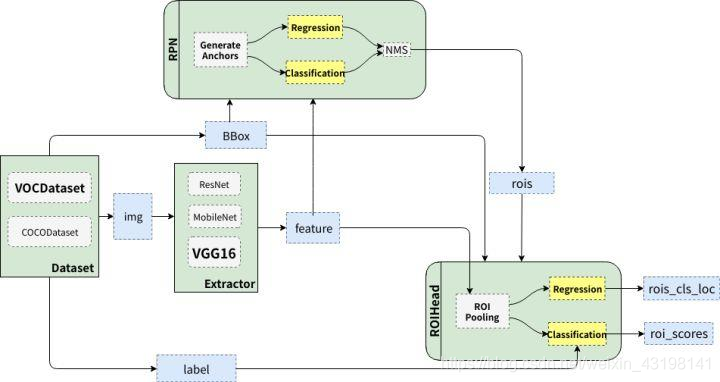
Faster RCNN
个人理解:two stage方法更符合解释,与传统识别方法与步骤相似,先通过ss或rpn方法获得候选box,再进行识别与迭代回归
one stage和two stage的区别,遍历的数量
- adaboost:图像金字塔生成检测框,或划窗生成
- fast rcnn:selective search生成检测框
- faster rcnn:region proposal network,3个尺寸3个长宽比
softmax分类获得positive anchors,也就相当于初步提取了检测目标候选区域box,对featuremap全局生成anchors,再根据positive confidence选取一定数量的正样本和负样本,用于stage two的classification and bounding box regression
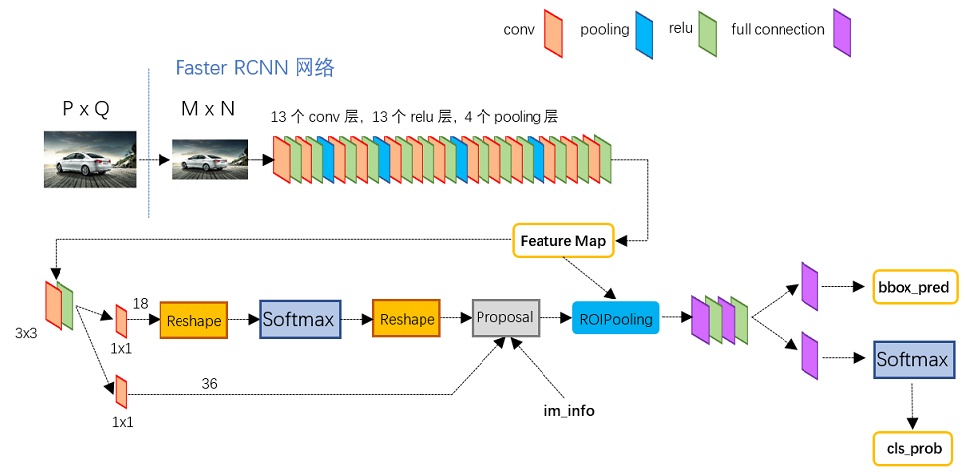
VGG16+Region Proposal Network+classfication/detection
输入:MxN
feature map:(M/16, N/16,512)
region proposal, feature map每个点propose 9个框,512维经过proposal转化为18和36,每个框2个score(negative score,positive score,与confidence类似),4个box coordinates
- (1,1,18):(M/16, N/16,2*9)
- (1,1,36):(M/16, N/16,4*9)
- 因此proposed anchors数量:M/16 * N/16 * 9
proposal layer,综合rpn的输出,计算出精准的proposal,输出对应bbox reg结果(例如300 anchors)作为proposal输出,检测网络严格意义上到此已经结束了
- 生成anchors,利用
- 按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors
- 限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界
- 剔除尺寸非常小的positive anchors
- 对剩余的positive anchors进行NMS(nonmaximum suppression),假设剩余200个candidate box
- 把candidate box坐标映射到每层feature map上
- 生成anchors,利用
ROIPooling
输入:共享网络输出512层feature map,feature map都根据condidate box coordinate,获取box对应的sub feature map中的信息,每个sub feature map(假设一个candidate box [512, 216,400])转化成fix length featue vector([1,7,7]--->[1,49]),具体方式如下
- 再将每个proposal对应的feature map区域水平分为
- 对网格的每一份都进行max pooling处理。
- 这样处理后,即使大小不同的proposal输出结果都是
- 再将每个proposal对应的feature map区域水平分为
输出维度(200,49), 其中200为设定的RPN输出的proposed box数量,49=7*7
dense layer:输出分类预测,bbox coordinate回归
训练:迭代方式,分批次训练
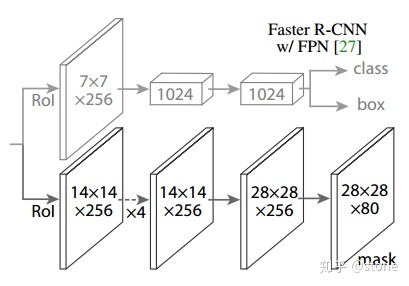
Mask RCNN
ResNet-FPN + Fast RCNN+Mask
Feature pyramid network,Resnet structure
实际上,下图少绘制了一个分支:M5经过步长为2的max pooling下采样得到 P6,作者指出使用P6是想得到更大的anchor尺度512×512。但P6是只用在 RPN中用来得到region proposal的,并不会作为后续Fast RCNN的输入。总结一下,ResNet-FPN作为RPN输入的feature map是 [P2, P3, P4, P5, P6] ,而作为后续Fast RCNN的输入则是 [P2, P3, P4, P5] 。
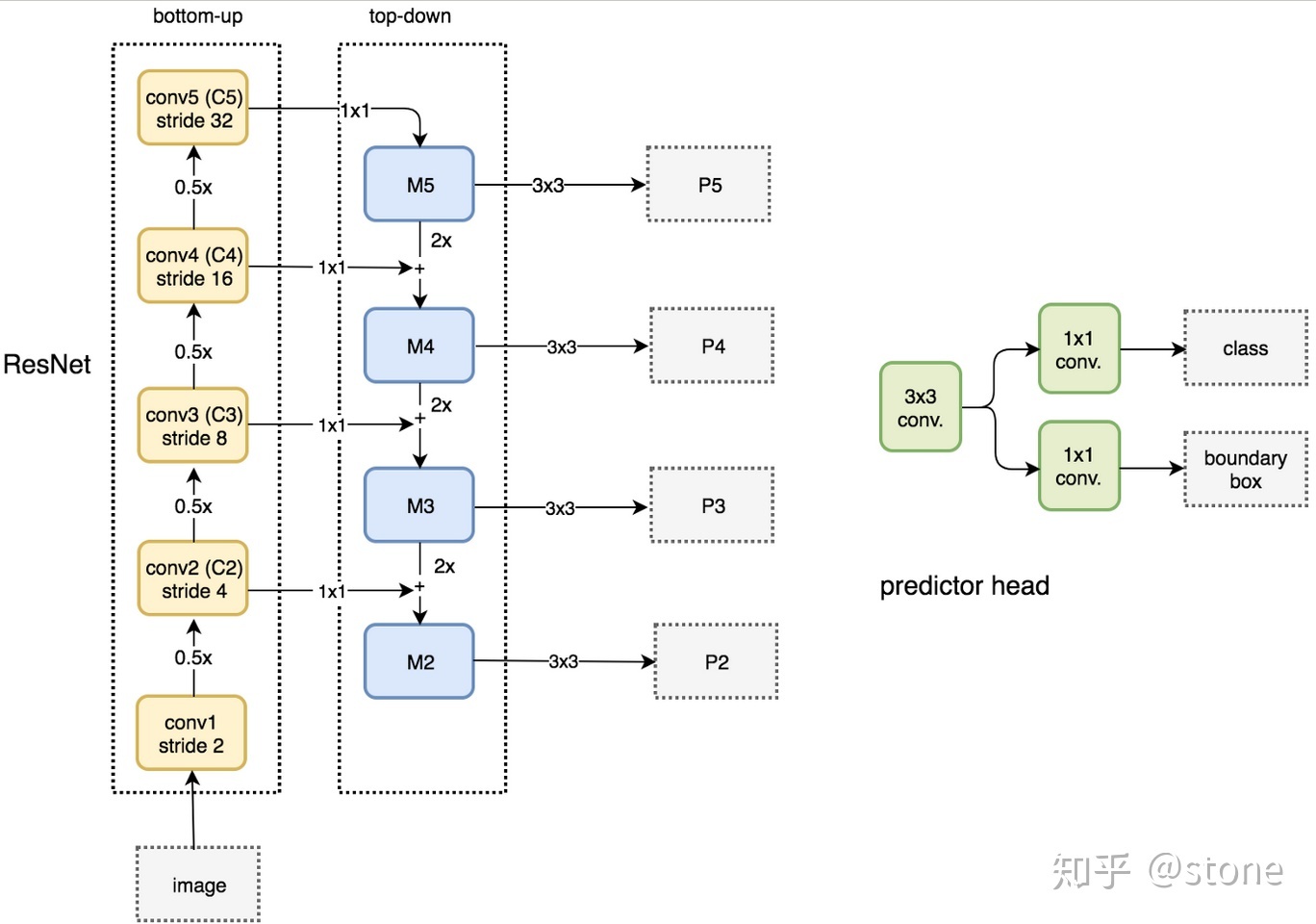
Resnet-FPN+Fast RCNN
将ResNet-FPN和Fast RCNN进行结合,实际上就是Faster RCNN的了,但与最初的Faster RCNN不同的是,FPN产生了特征金字塔[P2, P3, P4, P5, P6] ,而并非只是一个feature map。金字塔经过RPN之后会产生很多region proposal。这些region proposal是分别由 [P2, P3, P4, P5, P6] 经过RPN产生的,但用于输入到Fast RCNN中的是 [P2, P3, P4, P5] ,也就是说要在 [P2, P3, P4, P5] 中根据region proposal切出ROI进行后续的分类和回归预测。问题来了,我们要选择哪个feature map来切出这些ROI区域呢?实际上,我们会选择最合适的尺度的feature map来切ROI。具体来说,我们通过一个公式来决定宽w和高h的ROI到底要从哪个
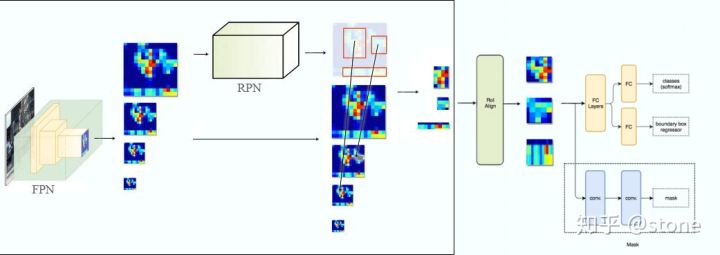
Resnet-FPN+Fast RCNN+Mask
Mask RCNN的构建很简单,只是在ROI pooling(实际上用到的是ROIAlign,后面会讲到)之后添加卷积层,进行mask预测的任务。
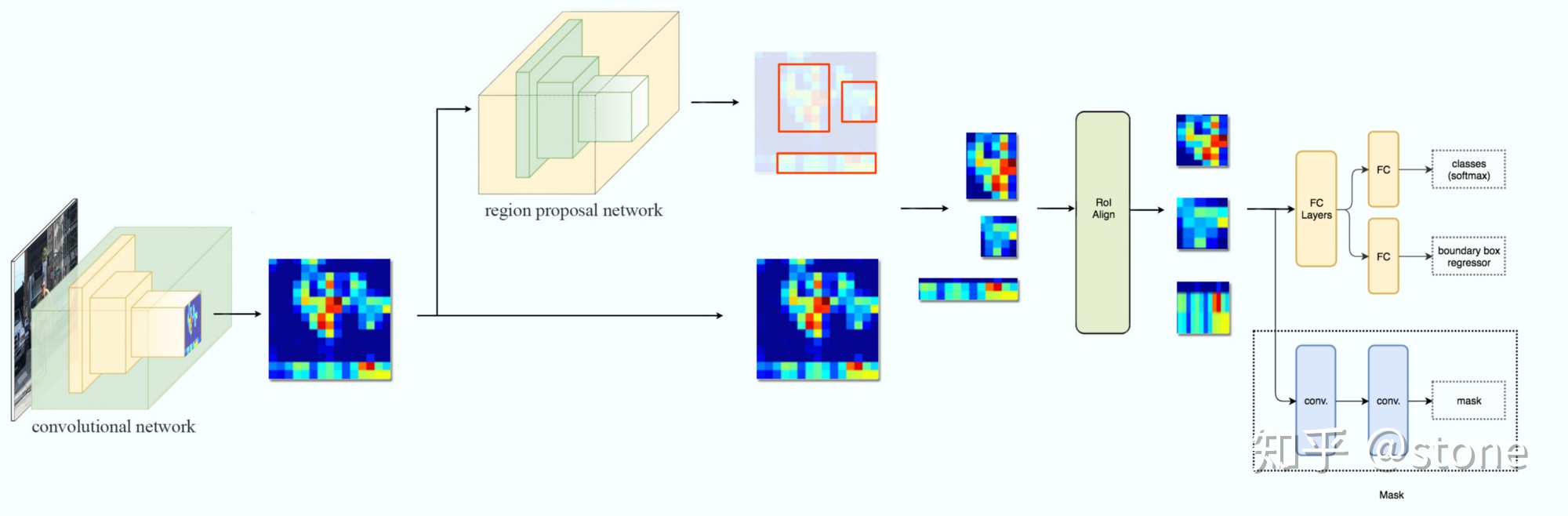
ROI Align
实际上,Mask RCNN中还有一个很重要的改进,就是ROIAlign。Faster R-CNN存在的问题是:特征图与原始图像是不对准的(mis-alignment),所以会影响检测精度。而Mask R-CNN提出了RoIAlign的方法来取代ROI pooling,RoIAlign可以保留大致的空间位置。
Region proposal方法中,有两次整数化过程:
- region proposal的xywh通常是小数,但是为了方便操作会把它整数化。
- 将整数化后的边界区域平均分割成 k x k 个单元,对每一个单元的边界进行整数化。
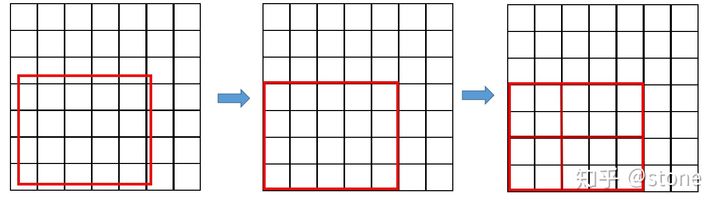
事实上,经过上述两次整数化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为“不匹配问题”(misalignment)。
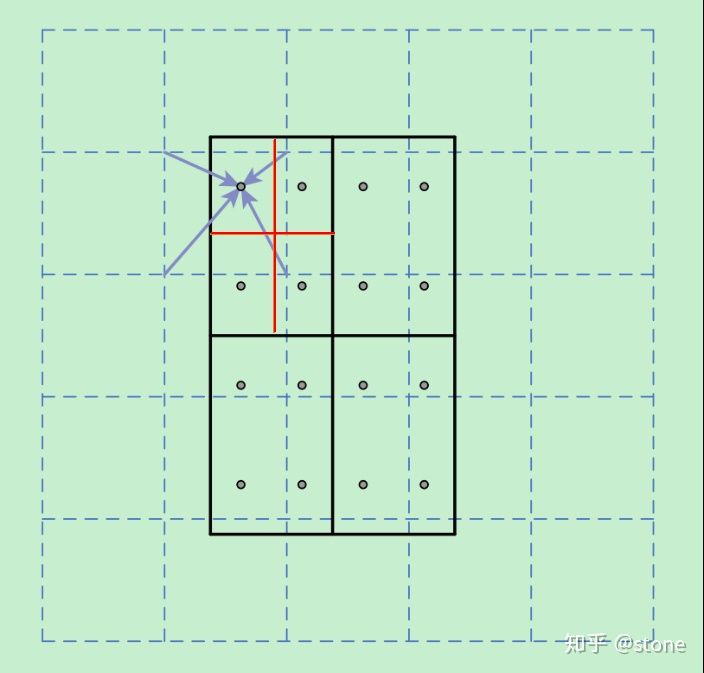
为了解决这个问题,ROI Align方法取消整数化操作,保留了小数,使用以上介绍的双线性插值的方法获得坐标为浮点数的像素点上的图像数值。但在实际操作中,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后进行池化,而是重新进行设计。
下面通过一个例子来讲解ROI Align操作。如下图所示,虚线部分表示feature map,实线表示ROI,这里将ROI切分成2x2的单元格。如果采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行maxpooling,就可以得到最终的ROIAlign的结果。
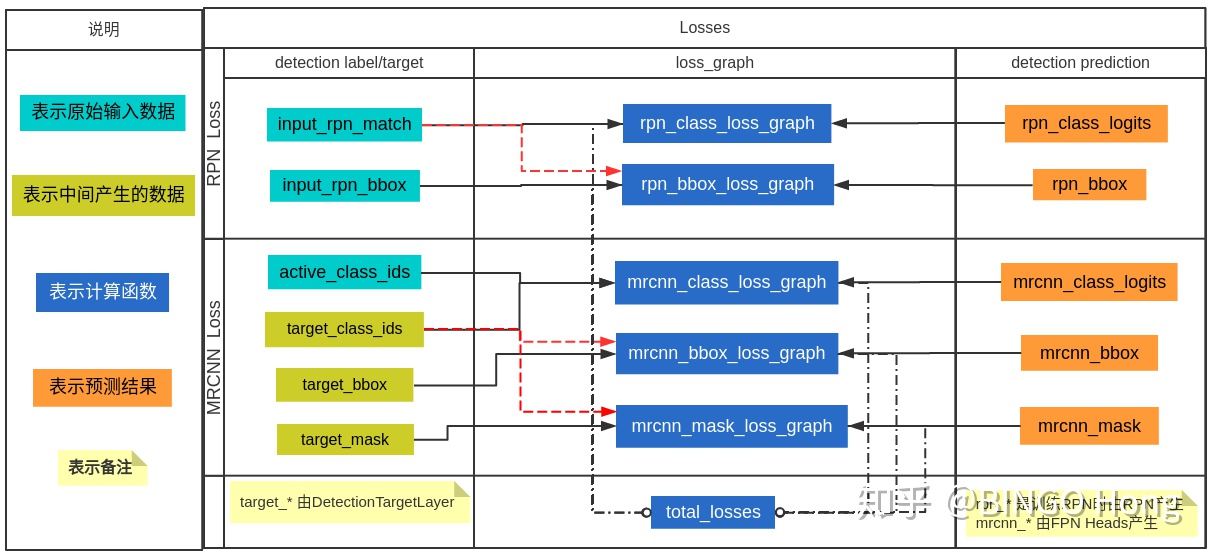
Loss definition
Mask RCNN loss定义与faster rcnn相同,只是多了mask loss,即
关于
这与FCN方法是不同,FCN是对每个像素进行多类别softmax分类,然后计算交叉熵损失,很明显,这种做法是会造成类间竞争的,而每个类别使用sigmoid输出并计算二值损失,可以避免类间竞争。实验表明,通过这种方法,可以较好地提升性能。
Cascade RCNN
CoupleNet
Object tracking
ROLO
SiamMask

Deep SORT
TrackR-CNN
Tracktor
JDE
Appendix
Activation:
Mish: A Self Regularized Non-Monotonic Neural Activation Function, state of the art activation,
- (-3,0):斜率稍大
- (,-3):接近0
- (0,): 接近1
Swish:x * sigmoid(x)
Maxout
GeLU
Loss:
- Focal loss
- smooth L1 loss
NMS:
- IOU_Loss:主要考虑检测框和目标框重叠面积。
- GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
- DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
- CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Preprocess:
- Mosaic