Signal enhancement reviewComparison on VoiceBank DatasetGenerative ModelWiener filterSEGANDSEGANMMSE-GANMetric-GANMetric-GAN+UNetGANWaveNetSEFLOWGF-VAEDIFFSEDiscriminative ModelDeep Feature LossWave-U-NetSelf adaption+Multi-head self attentionRDL-NetSounds of SilenceTSTNN
Signal enhancement review
信号降噪/增强长期以来都是研究热点,传统方法通过时频变换,预测噪声频谱,通过维纳滤波等方法弱化噪声,实现语音增强。
近几年,随着硬件计算能力、神经网络算法的发展,深度学习方法开始应用于SE,从早期的LSTM到近几年的GAN算法,都广泛应用于SE。
Comparison on VoiceBank Dataset
| Year | PESQ | CSIG | CBAK | COVL | SSNR | |
|---|---|---|---|---|---|---|
| Noisy | 1.97 | 3.35 | 2.24 | 2.63 | 1.68 | |
| Wiener | 1978 | 2.22 | 3.23 | 2.68 | 2.67 | 5.07 |
| SEGAN | 2017 | 2.16 | 3.48 | 2.94 | 2.8 | 7.73 |
| DSEGAN | 2019 | 2.39 | 3.46 | 3.11 | 3.50 | |
| MMSE-GAN | 2018 | 2.53 | 3.80 | 3.12 | 3.14 | |
| Metric-GAN | 2019 | 2.86 | 3.99 | 3.18 | 3.42 | |
| Metric-GAN+ | 2021 | 3.15 | 4.14 | 3.16 | 3.64 | |
| WaveNet | 2017 | 3.62 | 3.23 | 2.98 | ||
| SEFLOW | 2021 | 2.43 | 3.77 | 3.12 | 3.09 | 8.07 |
| DiffSE | 2021 | 2.43 | 3.63 | 2.81 | 3.00 | |
| Deep Feature Loss | 2018 | 3.86 | 3.33 | 3.22 | ||
| Wave-U-Net | 2019 | 2.62 | 3.91 | 3.35 | 3.27 | 10.05 |
| SELF-ADAPTATION+ MULTI-HEAD SELF-ATTENTION | 2020 | 2.99 | 4.15 | 3.42 | 3.57 | |
| RDL-Net | 2020 | 3.02 | 4.38 | 3.43 | 3.72 | |
| Sounds of Silence | 2020 | 3.16 | 3.96 | 3.54 | 3.53 | |
| T-GSA transformer | 2020 | 3.06 | 4.18 | 3.59 | 3.62 |
Generative Model
Wiener filter
传统滤波方法,例如简单的维纳滤波通过一个FIR滤波器,去除噪声的过程。 通过训练集的数据对信号和噪声的建模,然后通过前几个点的信息,预测当前时刻的噪声信号所占的比例,然后去除掉,剩下的就是预测的时序信号了。维纳滤波作为一种使用很广泛的滤波器,其变化的形式也有很多种,可以是单输入输出的,也可以是多输入输出的。
Wiener filter通过滤波(矩阵或者其他模型的形式)来从信号和噪声的混合中提取信号,维纳滤波的核心,就是计算这个滤波器,也就是解Wiener-Hopf方程。
SEGAN
SEGAN直接在时域对信号建模,通过端对端训练,实现信号增强
- the G network performs the enhancement. Its inputs are the noisy speech signal x together with the latent representation z, and its output is the enhanced version x' = G(x).
- chose the L1 norm, as it has been proven to be effective in the image manipulation domain
- add a secondary component to the loss of G in order to minimize the distance between its generations and the clean examples.
- the least-squares GAN (LSGAN) approach substitutes the cross-entropy loss by the least-squares function with binary coding (1 for real, 0 for fake).
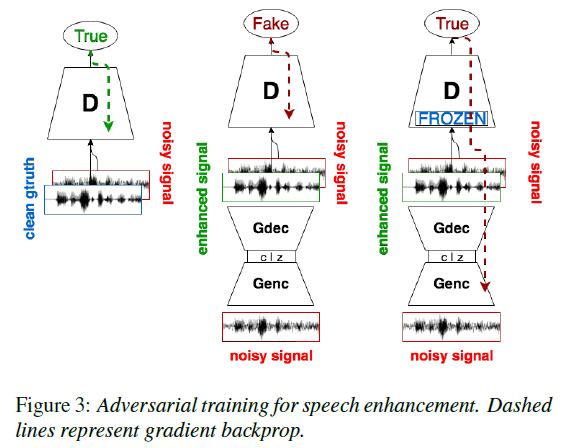
DSEGAN
在SEGAN的基础上,级联多个generator,实现multi-stage enhancement approach,效果好于one-stage SEGAN baseline(SEGAN)。为了适应multi-stage,loss需要叠加各个generator output的loss。
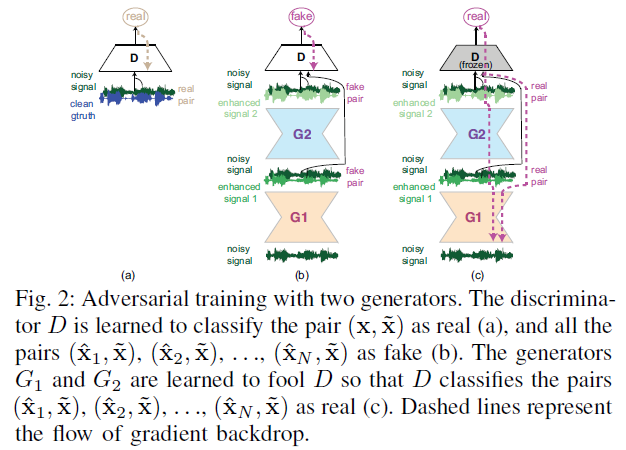
MMSE-GAN
作者通过实验发现Vanilla GAN无法很好的生成T-F mask/clean T-F representation,因此
- 在Vannila GAN的基础上修改了Generator的objective function,新增加了一项mean square error between the predicted and clean T-F representation
- 在VoiceBank数据集上验证,MMSE-GAN结果明显好于Vanilla GAN,而且能降低speech distortion
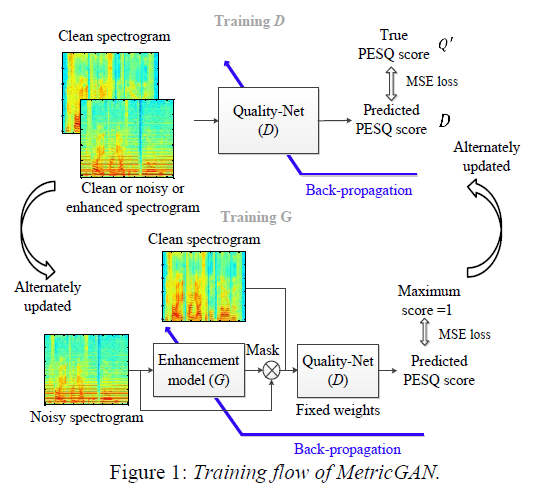
Metric-GAN
Vanilla GAN的loss function不是直接优化evaluation metrics,可能限制generator生成数据的质量,因此提出了MetricGAN:
- 修改GAN的loss function,将GAN中Discriminator Loss Label从以前的真假(0,1 离散的)换为连续的值,该值即为(normalized之后的)需优化的指标(如PESQ,范围为-0.5~4.5,归一化到0~1作为groundtruth of discriminator);
- 论文主要将PESQ和STOI两个评估指标作为metric,发现基于PESQ GT训练的网络,PESQ达到SOTA,同时STOI也在达到STOA;但就STOI GT训练的网络,STOI和PESQ测试结果均差于前者,但都优于论文对比的其它方法。
- 这种方式带来的问题是,理论上,针对不同的评估参数,都要重新训练(微调)网络,因为判别器的GT改变了。论文尝试了Multi-metric training,这是一个很难的训练问题,因为不同评估指标间可能有较强的相关性导致网络收敛较慢;但论文multi-metric依然得到不错的结果,虽然没有达到SOTA。
- 在VoiceBank数据集上与SEGAN,Deep Feature Loss等对比,四个指标中(PESQ、CSIG、CBAK、COVL)三个达到SOTA
Metric-GAN+
在MetricGAN的基础上,引入一些工程优化技巧,加速模型收敛与训练稳定性:
- 在D Loss新加入一项:最小化noisy speech and clean speech 之间的difference
- 训练D时,将之前生成的speech添加到输入数据集,history_portion设置为0.2,alternative training as algorithm 1 ( replay buffer )
- 由于信号频域存在相位信息,所有频域幅值不能直接相加,虽然时域noisy=clean+noise,但频域clean spec amp/noisy spec amp不一定小于1,并且不同的频段信号和噪声的谱之间的关系/差异不同;因此MetricGAN+引入了learnable sigmoid function,对不同的frequency bin的后处理参数(mask estimation)不同。注意,learnable不是可训练,是指针对不同的frequecy,参数是不一样的,是根据整个数据集,通过前处理(分析),获得不同frequency bin对应的alpha,论文图4给出了alpha取值;alpha akins to mean and std value of ImageNet.
UNetGAN
- 在GAN的基础上,将generator改为unet with dilated conv
- 在-20dB数据上做了实验,但只有objective evaluation,没有subjective evaluation,即使objective evaluation of PESQ improves,无法确定是否达到预期的降噪效果,可能降噪之后噪声在信号中依然占主导
WaveNet
Network
The intuition behind this configuration is two-fold.
- First, exponentially increasing the dilation factor results in exponential receptive field growth with depth. A 1, 2, 4, …, 512 block can be seen as a 1x1024 conv with receptive field of size 1024
- Second, stacking these blocks further increases the model capacity and the receptive field size.


Main features
μ-law companding transformation
- Quantizing 16-bit integer (65536 possible values) to 256 possible values,
- This non-linear quantization produces a significantly better reconstruction than a simple linear quantization scheme.
- For speech, we found that the reconstructed signal after quantization sounded very similar to the original.
- Preprocess dataset, downsampling from 16-bits to 8-bits
- For each time-step, final softmax outputs 256 values, regression problem like GPT
- Quantizing 16-bit integer (65536 possible values) to 256 possible values,
Gated activation units
- Output:
- In initial experiments, it is observed that this non-linearity worked significantly better than the rectified linear activation function for modeling audio signals
- Output:
Conditional wavenet
global conditioning
- Condition eg.: a single latent representation h
- Output:
local conditioning
- Condition eg.: a second timeseries h_t, a lower sampling frequency than the audio signal
- Output:
Complementary approach to increase the receptive field: Context stacks
- A context stack basically processes a longer part of the audio signal and locally conditions the model on that part
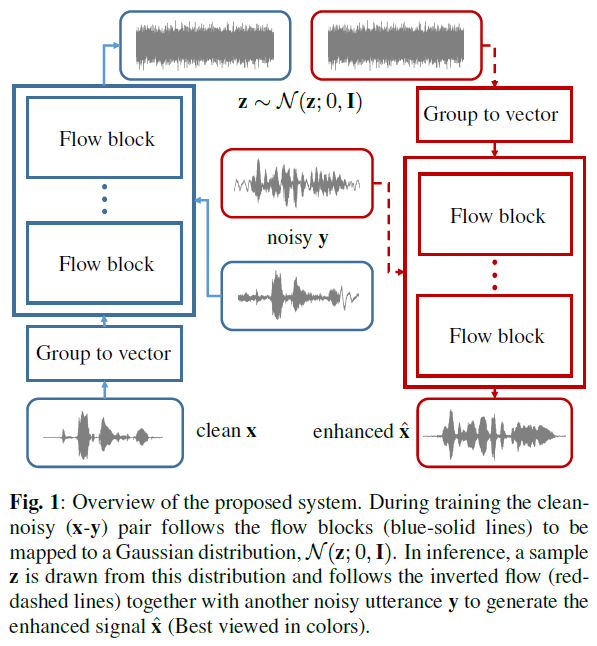
SEFLOW
目前唯一一篇完全基于Normalizing flow for speech enhancement:
- flow block/mapping function is constructed with similar DNN architecture as WaveNet
- u-law preprocessing to achieve nolinear input as WaveNet
- In contrast to WaveGlow, Input & condition of training & sampling process in SEFLOW都是时域信号. Since both signals are of the same dimension, no upsampling layer was needed.
GF-VAE
有点类似PCA,通过降维找到主成分(信号),从而实现speech enhancement/denoising
NF-VAE consists of an NF part and a VAE part.
- The NF part aims to transform the observed variable vector
- The VAE part then aims to find the low dimensional latent variable vector
- The NF part aims to transform the observed variable vector
Given the NF-VAE, a lower bound on the log-likelihood of
DIFFSE
核心方法,利用diffusion 可以利用condition combine不同域的特征(时域、频域),提出了supportive reverse sampling方法。
training过程不变:
input:clean signal
condition:
- pretrain: clean mel-spectral feature
- finetune: noisy spectral features,stft features
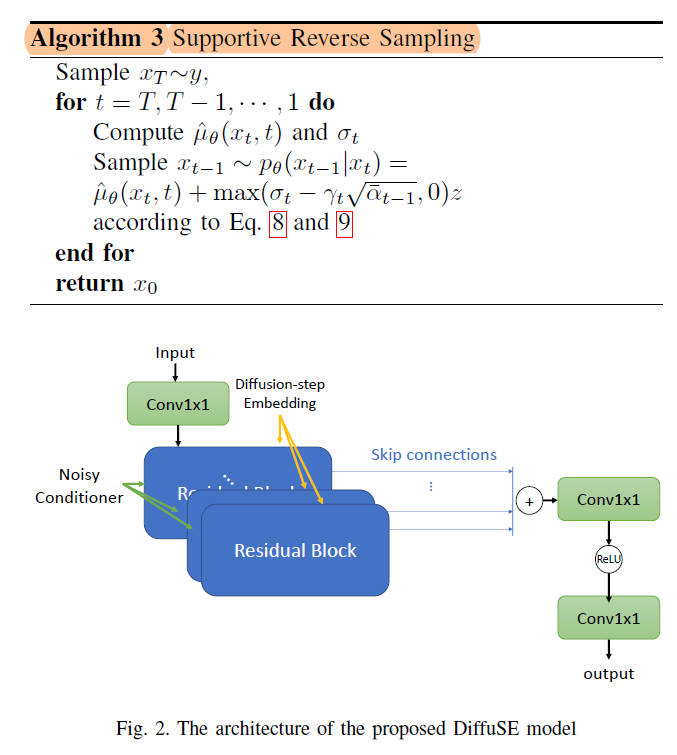
sampling过程,提出了supportive reverse sampling:
- input:y=clean signal+noise
- condition:noisy spectral features
- defined
Supportive Reverse Sampling
DDPM中定义:
SRS中:
- noisy speech signal is a combination of clean signal and background noise:
- define a new mean, which is the combination of original DDPM mean and noisy speech:
- hence, in order to keep the same overall mean and std as DDPM, 需减掉新定义的mean引入的std,因此remaining part of noise is
Discriminative Model
Deep Feature Loss
背景:
- 使用的基本的fully convolutional network,直接对时域信号增强,不需要condition和expert knowledge;输入是noisy signal,输出是enhance signal;
- 传统方法直接将将clean signal作为groundtruth,计算enhance signal与clean signal之间的regression loss,训练网络实现降噪
但是conventional loss的方式,信号增强效果有待提升,因此作者提出了deep feature loss,网络结构不变,仅将conventional loss修改为deep feature loss:
- eg. conventional loss:
- 其中
- 相对于conventional loss, deep feature loss更复杂,能够捕捉和评估增强信号在不同scale and feature上相对clean signal的差异,因此训练得到的fully convolutional network实现的更好的增强效果
- 在Voicebank上的实验,达到当时(2018)的SOTA效果
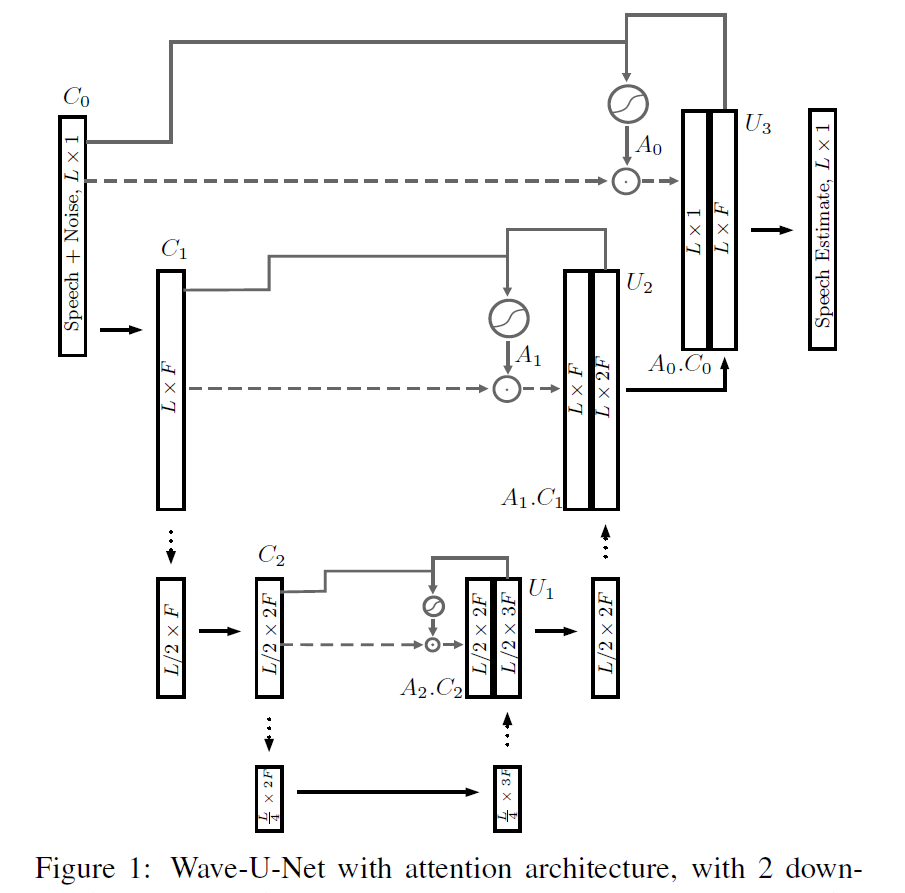
Wave-U-Net
- Vanilla U-Net在图像分割等领域应用广泛,通过将attention machanism引入U-Net,可以很好的解决语音信号的长时依赖问题。
- Wave-U-Net网络由U-Net+attention machanism组成,引用在语音增强上,输入和输出都是时域信号,通过regression loss训练网络,实现信号降噪和增强;同时对比L1和L2 loss、u-law预处理的效果
- 在Voicebank上测试结果,效果比WaveNet、SEGAN、Deep Feature Loss更好
Self adaption+Multi-head self attention
We adopt the multi-task-learning strategy for incorporating speaker-aware feature extraction for speech enhancement.
其实就是一个大网络,针对不同的要求,融合了多个不同模块;例如引入multi-head self attention(MHSA)/ BLSTM for long-time dependency, CNN for feature extraction
self-adaptation的是通过speaker classification实现的,引入的classification task,使网络训练是能区分不同的speaker;同时,model adaptation to the target speaker improves the accuracy,make the model can be adopted to unknown speakers without any auxiliary guidance signal in test-phase.
Multi-task:
- classification:cross entropy loss
- regression:
在Voicebank上的实验,达到SOTA,比回归模型结果都好

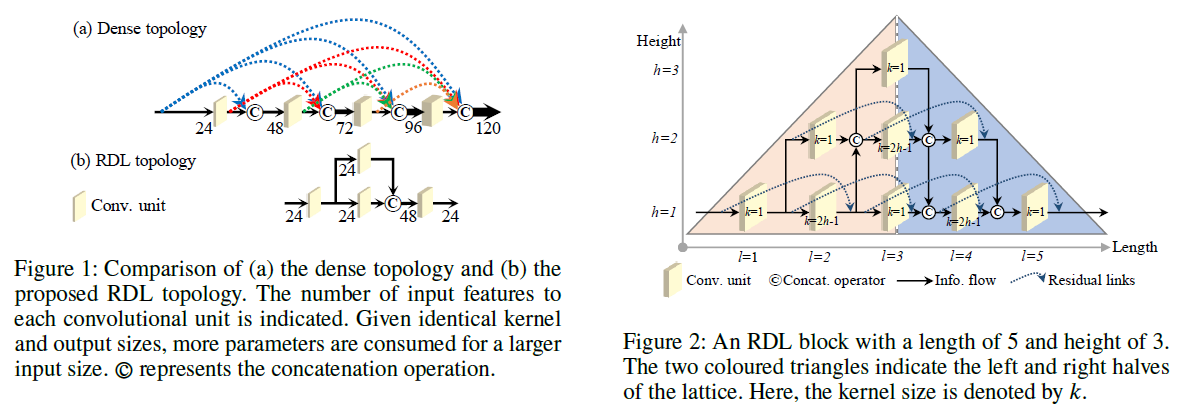
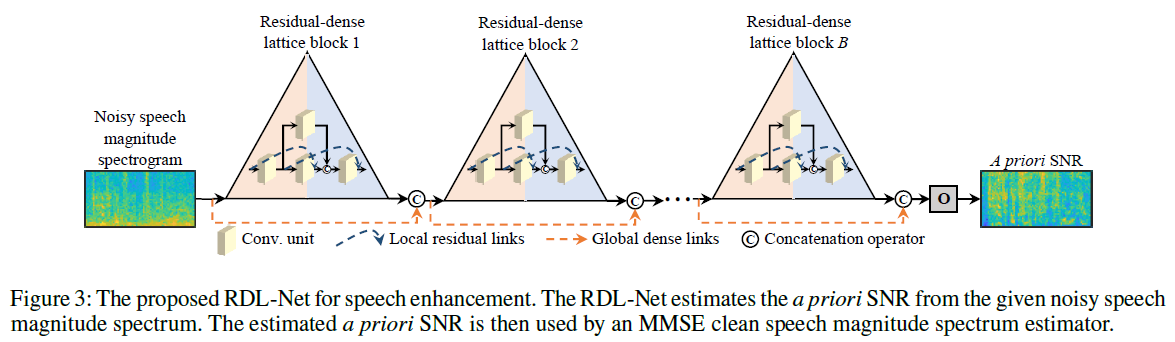
RDL-Net
背景:
- 目前的densenet、DenseRNet、MLN等网络结构,block间的连接太多,feature re-usage现象严重
- 当网络过深时,参数多,over-allocating parameters for feature re-usage.
因此,提出了Residual-Dense Lattice block,类似residual block,只是分支减少,以及分支 间的连接减少,有点类似通过NAS搜索出来的block/architecture。
- 通过工程上的不同尝试,例如training strategy,ablation study of block construction and connection,训练得到最优模型
- 网络学习的是prior SNR/noise spectrum,再通过MMSE clean speech magnitude spectrum estimator,获得denoised signal
- 在Voicebank上的测试结果,好于MetricGAN、deep feature loss等
- 同时记录了flops,参数少了,层数少了,自然flops更少
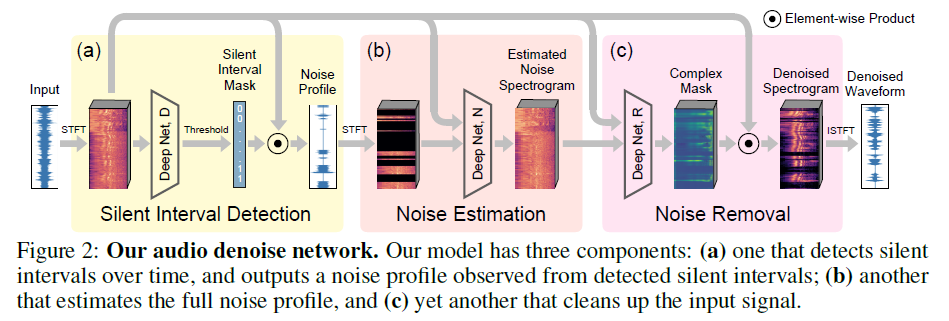
Sounds of Silence
通常语音信号中,每个词或句子间存在间隔,通过对间隔的识别以及间隔期间噪声的分析,估计整个信号中噪声的分布,可以实现降噪。因此文章提出了一个可端到端训练的回归模型来实现降噪。
- Sounds of Silence可以看做是一个模型,但包含三个子模块,每个子模块赋予不同的功能,但第一个silent interval detection模块没有贡献loss(作者也试了将引入第一个模块的loss:Sec3.2&3.3,但发现效果反而更差;对该现象的解释为natural emergence of silent intervals)。
- 因此Sounds of silence可以看做是two-stage regression network:noise estimation & noise removal,训练时优化sum of absolute regression loss
- 在Voicebank做了对比试验,结果比WaveNet,SEGAN,MetricGAN,Self-adaptive都要好
TSTNN
- The proposed model is composed of an encoder, a two-stage transformer module (TSTM), a masking module and a decoder.
- The encoder maps input noisy speech into feature representation.
- The TSTM exploits four stacked two-stage transformer blocks to efficiently extract local and global information from the encoder output stage by stage
- The masking module creates a mask which will be multiplied with the encoder output. Finally, the decoder uses the masked encoder feature to reconstruct the enhanced speech.