目录
Transformer2017 Attention is All You NeedEncoder and Decoder StacksEncoderDecoderAttentionWhy self-attentionCompare with RNNCompare with CNN2019 BERTEmbeddingsEncoder stackAttention layerTrainingEleven downstream tasksGPTEmbeddingDecoder stackAttention layerTrainingGPT2GPT3Reference
Transformer
Transformer的出现时预训练模型发生质变的关键因素,它的前任LSTM相较而言无法捕捉更长的语义信息。
2017 Attention is All You Need
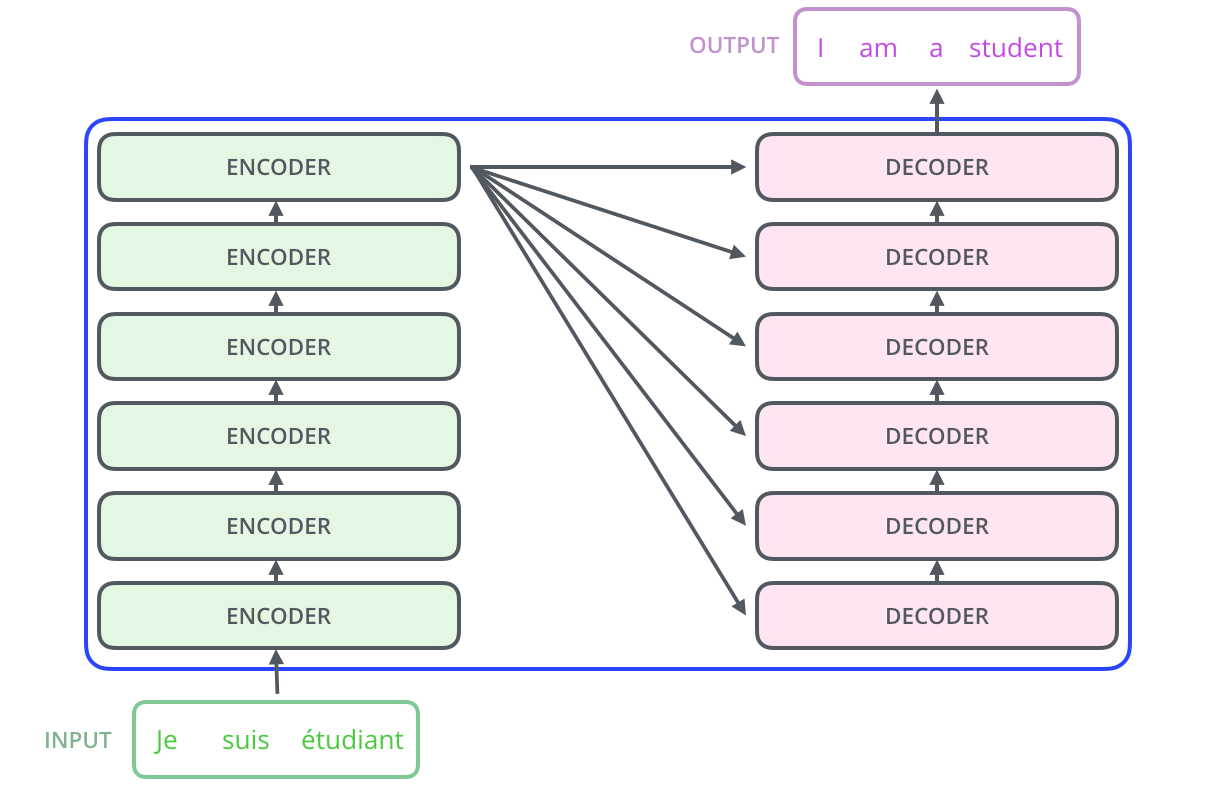
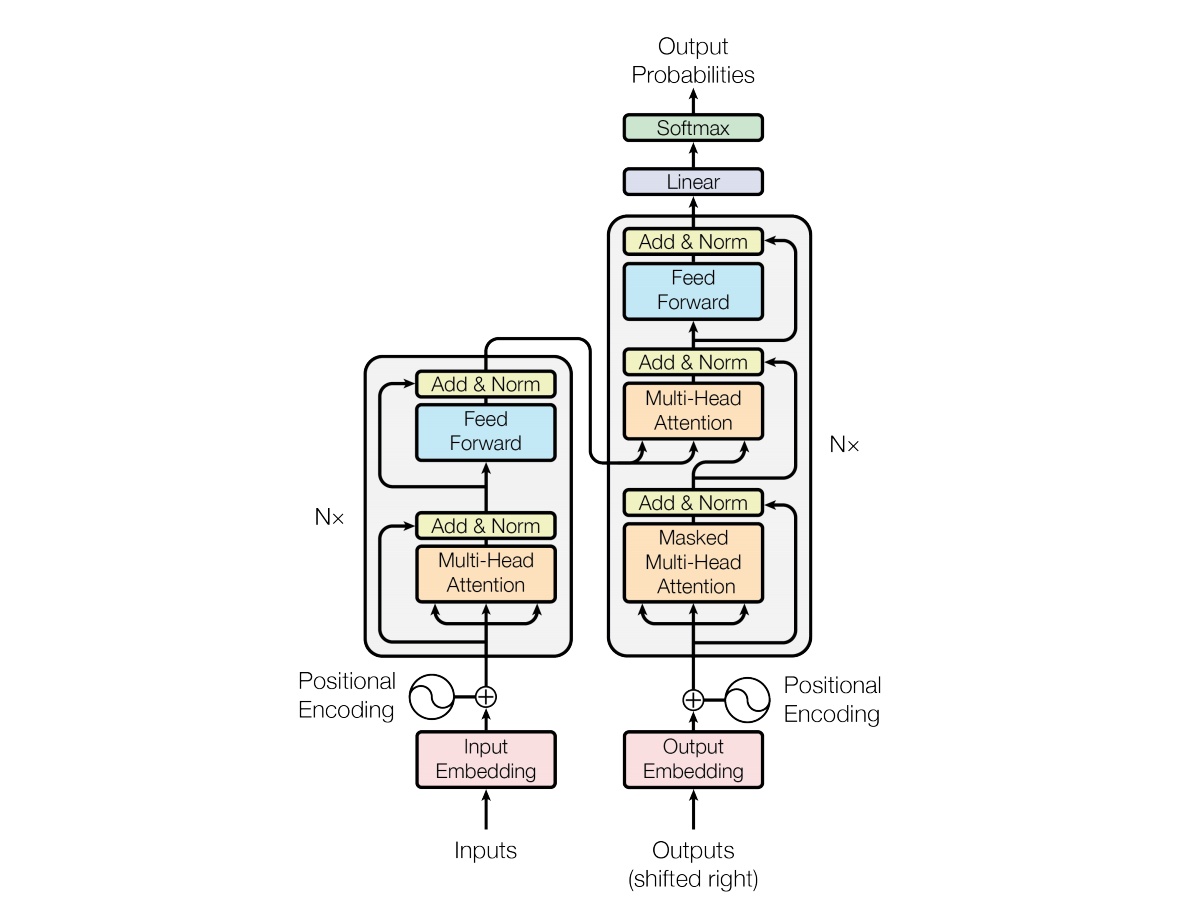
Encoder and Decoder Stacks
Encoder
- The encoder is composed of a stack of N = 6 identical layers.
- Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network.
Decoder
- The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack.
- We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i. (sequence mask/attention mask)
Attention
Scaled dot-product attention
- padding mask/ position mask: mask out padded tokens, set to
- sequence mask: determines unidirectional or bidirectional transformer
- attention mask = padding mask + sequence mask
- padding mask/ position mask: mask out padded tokens, set to
Multi-head attention: similar as group/depth separable convolution
Embeddings
- token embedding, use learned embeddings to convert the input tokens and output tokens to vectors (即embedding weight是通过网络学习的)
- Positional encoding: eg. The 128-dimensional positonal encoding for a sentence with the maximum lenght of 50. Each row, 即positional embedding规则是固定的
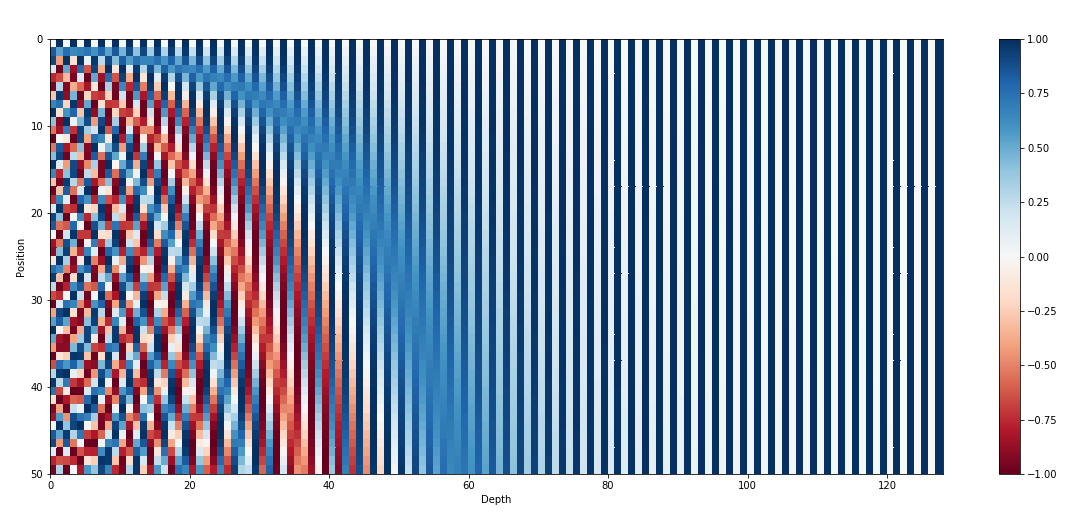
Application of attention
encoder 中的attention:只使用padding mask,sequence mask ==1, 即attention mask=padding mask,
decoder中:
- 自己的masked multi-head attention中,同时使用padding mask和sequence mask,即attention mask = padding mask + sequence mask,
- encoder与decoder连接层Multi-head attention中,只使用padding mask,sequence mask ==1, 即attention mask=padding mask,
- 自己的masked multi-head attention中,同时使用padding mask和sequence mask,即attention mask = padding mask + sequence mask,
Why self-attention
As side benefit, self-attention could yield more interpretable models. Not only do individual attention heads clearly learn to perform different tasks, many appear to exhibit behavior related to the syntactic and semantic structure of the sentences.

Compare with RNN
A self-attention layer connects all positions with a constant number of sequentially executed operations, whereas a recurrent layer requires O(n) sequential operations. In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n is smaller than the representation dimensionality d, which is most often the case with sentence representations used by state-of-the-art models in machine translations, such as word-piece and byte-pair representations. To improve computational performance for tasks involving very long sequences, self-attention could be restricted to considering only a neighborhood of size r in the input sequence centered around the respective output position.
Compare with CNN
A single convolutional layer with kernel width k < n does not connect all pairs of input and output positions. Doing so requires a stack of O(n=k) convolutional layers in the case of contiguous kernels, or O(logk(n)) in the case of dilated convolutions, increasing the length of the longest paths between any two positions in the network. Convolutional layers are generally more expensive than recurrent layers, by a factor of k.
2019 BERT
BERT系列的模型为自编码语言模型,其通过随机mask掉一些单词,在训练过程中根据上下文对这些单词进行预测,使预测概率最大化。
Embeddings
classification,
Input
- Token embedding: 30522D
- Positional embedding: 512D
- Type/segment embedding: 2D
output
- first column, dense layer, 2 units
question answer
Encoder stack
只使用transformer的encoder模块的级联,没有使用sequence mask,因此attention mask=padding mask;
sequence mask的作用是防止前面的token看见未来的token,因此当不使用sequence mask时,self-attention自然天然的能实现bidirectional;
与bert对比的是GPT1,其使用transformer的decoder模块,同时引入sequence mask和padding mask,因此GPT1是unidirectional;
这也是BERT论文中提到的:
- OpenAI GPT uses a left-to-right transformer
- ELMo uses the concatenation of independently trained left-to-right and right-to-left LSTMs to generate features for downstream tasks.
- BERT representations are jointly conditioned on both left and right context in all layers.
Attention layer
- Dropout:前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征;但网络的结构维度没有改变,与之相反的是剪枝与蒸馏 。
- Multi-head attention: 输入均为上一个encoder的输出,只使用padding mask (因为填充的token无有效信息可提取)
- 事实上bert代码里定义了sequence mask,但是全1矩阵,相当于未引入,即全1矩阵保证了bidirectional transformer
- we denote the number of layers (i.e., Transformer blocks) as L, the hidden size as H, and the number of self-attention heads as A. We primarily report results on two model sizes: BERTBASE (L=12, H=768, A=12, Total Parameters= 110M), H=768为12个head的总hidden size,则hidden size per head=64. 事实上不管是单头还是多头,只要总hidden size一样,不同的head结构,参数量计算量都一致。
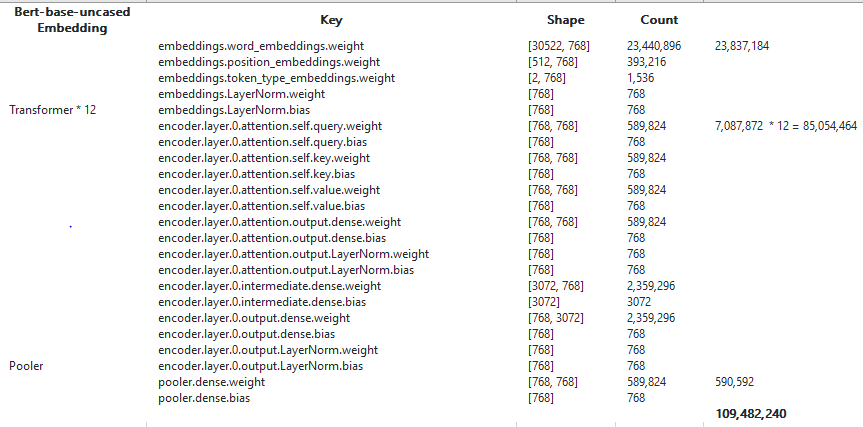
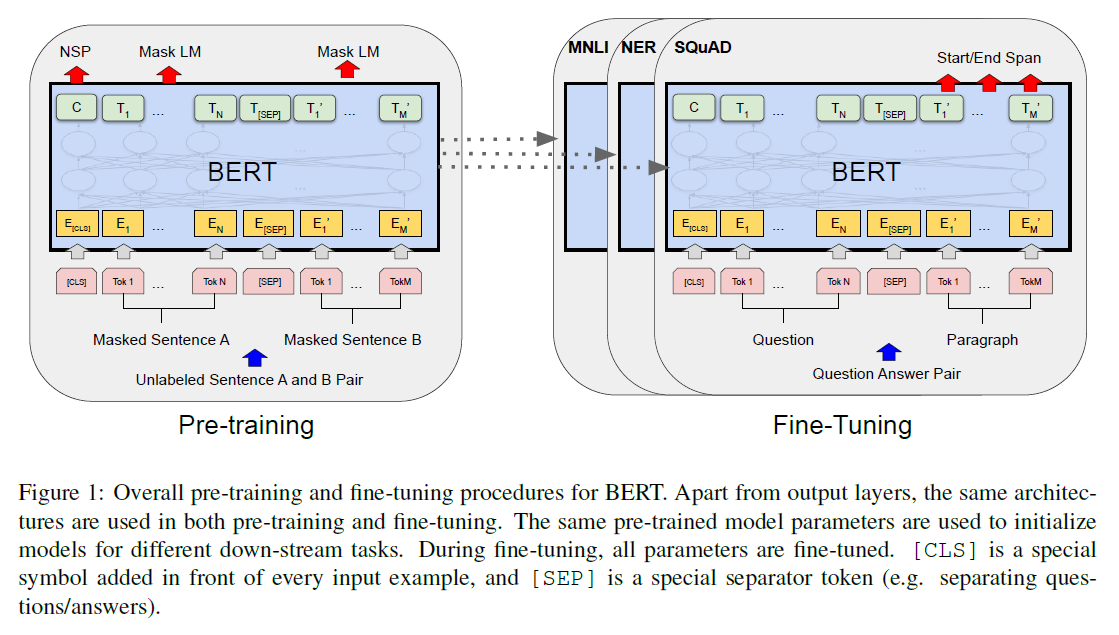
Training
embedding、input encoding是关键,比如引入的positional embedding
BERT的本质上是通过在海量的语料的基础上运行自监督学习方法,为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习;在以后特定的NLP任务中,在自监督学习获得的预训练模型基础上,微调模型即可。
因此,BERT训练分为两个阶段:
Pre-training:
- Two training tasks: Masked language model, Next sentence Prediction
- Runs several days on 64 TPU
- The training loss is the sum of the mean masked LM likelihood and the mean next sentence prediction likelihood, both of them are cross entropy loss.
Fine-tuning
- 11 NLP tasks and obtains new state-of-the-art results
- Runs at most 1 hour on a single Cloud TPU, or a few hours on a GPU
In contrast to denoising auto-encoders, we only predict the masked words rather than reconstructing the entire input.
Eleven downstream tasks
GLUE: General language understanding evaluation benchmark, eight classification tasks
- MNLI
- QQP
- QNLI
- SST-2
- CoLA
- STS-B
- MRPC
- RTE
- WNLI, excluded, there are issues with the construction of this dataset
SQuAD v1.1: stanford question answering dataset, a collection of 100k crowdsourced question/answer pairs. Given a question and a passage from Wikipedia containing the answer, the task is to predict the answer text span in the passage.
SQuAD v2.0: The SQuAD 2.0 task extends the SQuAD 1.1 problem definition by allowing for the possibility that no short answer exists in the provided paragraph, making the problem more realistic.
SWAG: Given a sentence, the task is to choose the most plausible continuation among four choices.
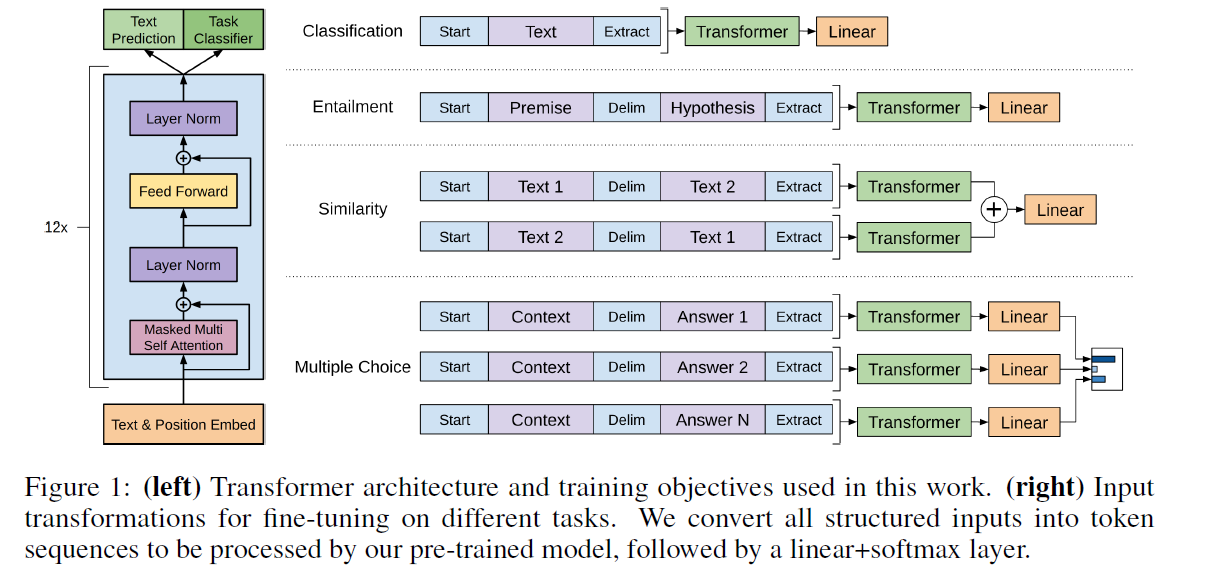
GPT
GPT,全称是Generative Pre-training,顾名思义,就是预训练模型。
在GPT出现之前,通用的使用预训练的方式是word2vec,即学习词语的表达。而在GPT出现之后,通用的预训练方式是预训练整个网络然后通过微调(fine-tune)去改进具体的任务。
这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。这种机制叫做自回归(auto-regression),同时也是令 RNN 模型效果拔群的重要思想。
Embedding
Positional embedding: We used learned position embeddings instead of the sinusoidal version proposed in the original work. 1024D
Token embedding: We used learned token embeddings. 50257D
输入和输出共享
Decoder stack
Our model largely follows the original transformer work [62]. We trained a 12-layer decoder-only transformer with masked self-attention heads (768 dimensional states and 12 attention heads).
- Masked multi-self attention: attention mask = padding mask + sequence mask, sequence mask为下三角矩阵,保证unidirectional left-to-right transformer
Attention layer
- Dropout
- Masked multi-self attention
假设
,则 ,再与 相乘后仍然是
后仍是768到768的映射,相当于dense layer,该步映射是GPT-attention相对BERT-attention更多的一层
Training
在未标注数据上的学习这一部分,需要学习一个语言模型,所谓的语言模型,就是依据前面的context,去预测下一个词。如公式所示:
在得到了基于Transformer的模型之后,针对具体的某个任务,假设输入和输出分别是x和y,那么我们在transformer的输出上再加一层:
最终在downstream task上finetune时把语言模型的目标函数当做辅助目标函数来增强最终的效果,总损失函数定义为
只做分类任务
GPT2
GPT-2论证了什么事情呢?对于语言模型来说,不同领域的文本相当于一个独立的task,而如果把这些task组合起来学习,那么就是multi-task学习。所特殊的是这些task都是同质的,即它们的目标函数都是一样的,所以可以统一学习。那么当增大数据集后,相当于模型在更多领域上进行了学习,即模型的泛化能力有了进一步的增强。
The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. Our largest model, GPT-2, is a 1.5B parameter Transformer that achieves state of the art results on 7 out of 8 tested language modeling datasets in a zero-shot setting but still underfits WebText.
Language Models are Unsupervised Multitask Learners,zero-shot是指没有gradient update,但有引导
Dataset:
- 40G ,WebText
任务:
- 分类:The Children’s Book Test (CBT) (Hill et al., 2015) was created to examine the performance of LMs on different categories of words: named entities, nouns, verbs, and prepositions.
- The LAMBADA dataset,The task is to predict the final word of sentences which require at least 50 tokens of context for a human to successfully predict.
- The Conversation Question Answering dataset (CoQA) Reddy et al. (2018) consists of documents from 7 different domains paired with natural language dialogues between a question asker and a question answerer about the document. CoQA tests reading comprehension capabilities and also the ability of models to answer questions that depend on conversation history (such as “Why?”).
- Translation:We test whether GPT-2 has begun to learn how to translate from one language to another
- SQUAD:question answering
GPT3
Language Models are Few-Shot Learners
Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art finetuning approaches.
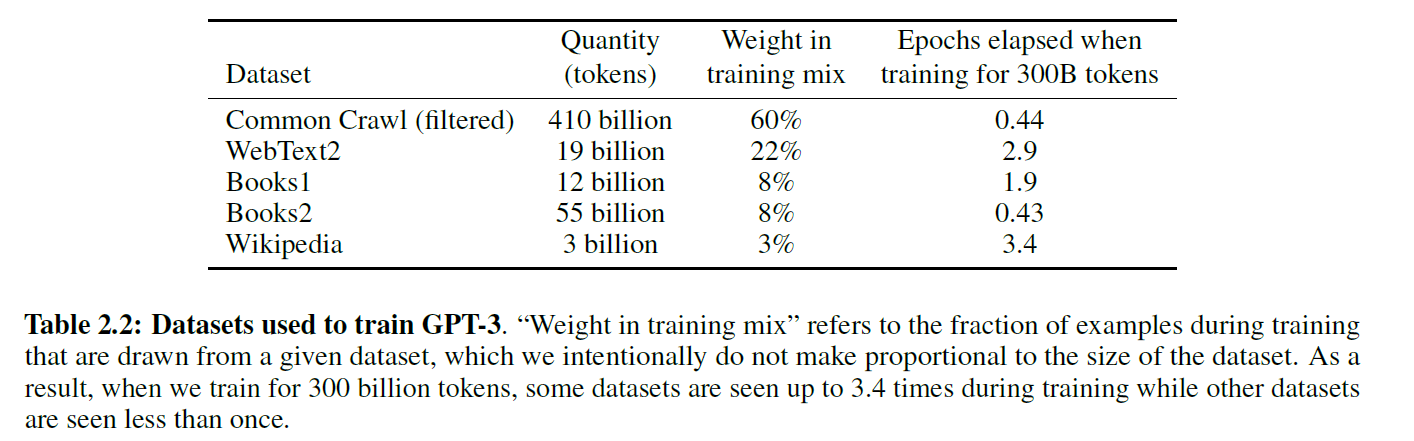
Dataset:
- CommonCrawl:covering 2016 to 2019, constituting 45TB of compressed plaintext before filtering and 570GB after filtering, roughly equivalent to 400 billion byte-pair-encoded tokens.
- expanded version of the WebText dataset [RWC+19]
- two internet-based books corpora (Books1 and Books2)
- English-language Wikipedia.
For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
- translation
- question-answering
- unscrambling words
- using a novel word in a sentence
- performing 3-digit arithmetic.
- reading comprehension

Reference