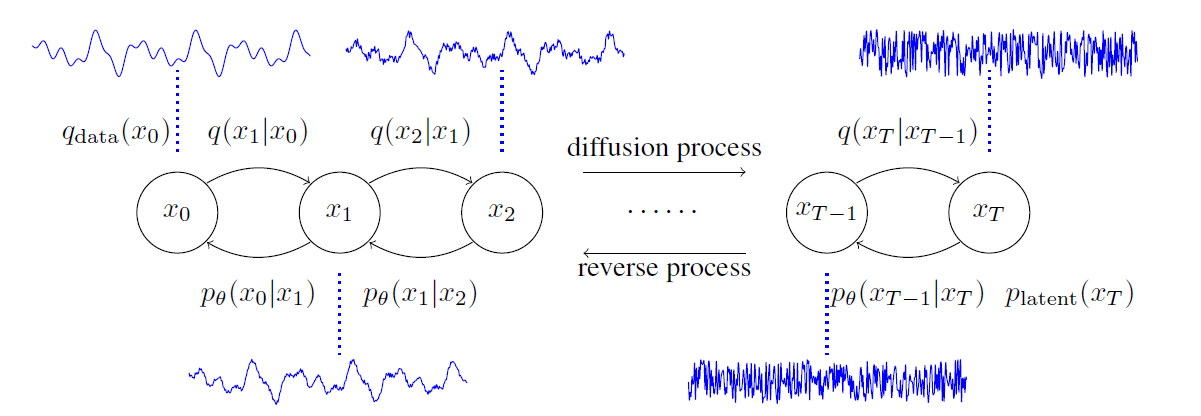
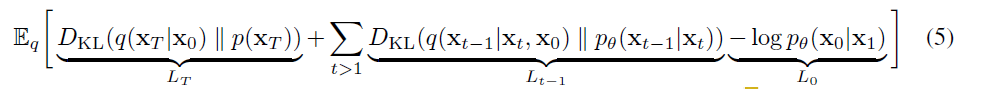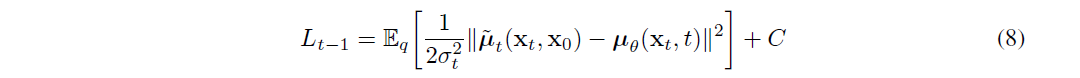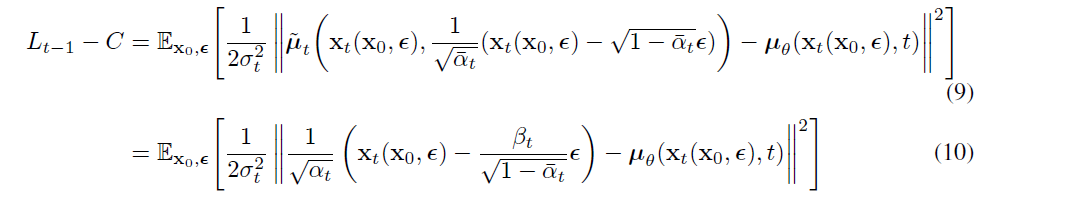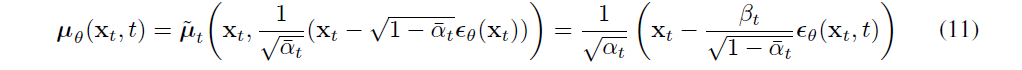diffusion process: also called forward process, training process, represented by
reverse process: also called sampling process, inference process, represented by
注意:
diffusion process:is fixed to a Markov chain that gradually adds Gaussian noise to the data according to variance schedule , 即变换前后满足高斯分布,当前状态只与前一时刻有关; 下一小节将给出diffusion过程的分布预定义形式,即variance schedule是自定义的constant;且从上图可以看出diffusion过程与无关,只是为了求loss,将作用在forward input上,后续将具体介绍
reverse process: is defined as a Markov chain with learned Gaussian transition starting at ,但reverse过程的mean and std是与相关的函数,为了使尽量接近,需要找到mean和std的最佳定义,使likelihood of 最大,这也是diffusion model的loss定义,后续将具体介绍
预定义
Diffusion Process
根据Diffusion Model[1]的定义,定义了diffusion process is fixed to a Markov chain that gradually adds Gaussian noise to the data according to variance schedule :
注意此处不是阶乘,代表嵌套的意思,类似normalizing flow里的表达
Reverse Process
根据定义,sampling/reverse process is defined as a Markov chain with learned Gaussian transition starting at :
注意此处不是阶乘,代表嵌套的意思,类似normalizing flow里的表达
Loss
Reverse process is parameterization, 为了使reverse process尽可能的得到fidelity result,则需要找到使最接近分布的参数,即采用maximize log likelihood estimation,等价于minimize negative log likelihood。
下式中的通常很难准确求解,Sampling process start from , 则:
故通过minimize variational bound on log likelihood求解 (该diffusion求解过程is known as the variance preserving forward SDE), log likelihood定义为:
有相似的结果,The first choice is optimal for , and thes econd is optimal for deterministically set to one point. These are the two extreme choicesc orresponding to upper and lower bounds on reverse process entropy for data with coordinatewise unit variance[1].
The complete sampling procedure resembles Langevin dynamics with as a learned gradient of the data density. 同时,Eq10.可简化为:
which resembles denoising score matching over multiple noise scales indexed by t. 上式 is equal to (one term of) the variational bound for the Langevin-like reverse process, we seethat optimizing an objective resembling denoising score matching is equivalent to using variational inference to fit the finite-time marginal of a sampling chain resembling Langevin dynamics