Diffusion
DDPM
The Ornstein–Uhlenbeck process (OUP) is a unique Gaussian, stationary diffusion process. Originating as a model for the Brownian motion of a particle, it has a wide range of applications in biology and elsewhere.
20210914-DDPM完全解读-周阅
DDPM完全解读名词解析预定义Diffusion ProcessReverse ProcessLoss推导q(x_T|x_0)q(x_{t-1}|x_t,x_0)p_{\theta}(x_{t-1}|x_t)首先考虑std其次考虑mean整合Reference
https://yuezhou-oh.github.io/blog/paperreading/Understanding_diffusion_model.html
Evaluation:
- Inception Score (IS): it measures how well a model captures the full ImageNet class distribution while still producing individual samples that are convincing examples of a single class.
- Fréchet Inception Distance (FID): provides a symmetric measure of the distance between two
image distributions in the latent space
DDIM
Denoising Diffusion Implicit Model: deterministic sampling methods
💡
保证noising/diffusion的目标分布与DDPM一致(),构建新的采样分布替代马尔科夫链,可以无需依赖过长的MC,并可以通过trajectory控制reverse生成路径,加快生成速度,trade off between computation and sample quality

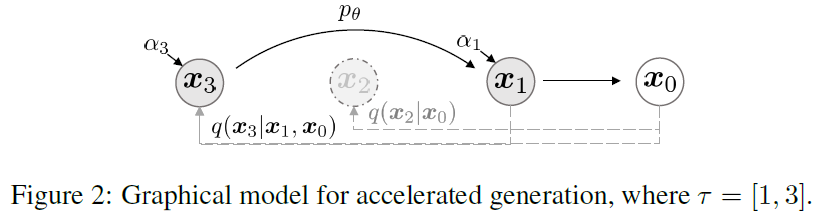
Denoising Diffusion Implicit Models
Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a...
Classifier Guidance Diffusion
论文中包括深入浅出的对background和previous work的review和theoretical illustration,现在大多数论文里都用协方差矩阵表示log高斯分布()
- 2021年OpenAI在「Diffusion Models Beat GANs on Image Synthesis」中提出Classifier Guidance,使得扩散模型能够按类生成。
- 后来「More Control for Free! Image Synthesis with Semantic Diffusion Guidance」把Classifier Guidance推广到了Semantic Diffusion,使得扩散模型可以按图像、按文本和多模态条件来生成,例如,风格化可以通过content和style两者共同进行引导,这些都是通过梯度引导来实现。
训练与推理过程中,
- 训练时,Classifier Guidance需额外添加一个classifier的梯度来引导,guide the diffusion sampling process towards an arbitrary class label
- 推理时每一步都需要额外计算classifier的梯度,Our classifier architecture is simply the downsampling trunk of the UNet model with an attention pool at the 8x8 layer to produce the final output

Diffusion Models Beat GANs on Image Synthesis
We show that diffusion models can achieve image sample quality superior to the current state-of-the-art generative models. We achieve this on unconditional image synthesis by finding a better...
Classifier-Free Diffusion Guidance
https://openreview.net/pdf?id=qw8AKxfYbI
💡
Classifier-Free Guidance的核心是通过一个隐式分类器来替代显示分类器,而无需直接计算显式分类器及其梯度。
Classifier Guidance 使用显式的分类器引导条件生成有几个问题:
- 一是需要额外训练一个噪声版本的图像分类器(实际实现上大多是基于diffusion model的部分网络加上classify layer组成)。
- 二是该分类器的质量会影响按类别生成的效果。
- 三是通过梯度更新会导致对抗攻击效应(生成时用到了梯度)
In initial experiments with unconditional ImageNet models, we found it necessary to scale the
classifier gradients by a constant factor larger than 1. When using a scale of 1, we observed that the classifier assigned reasonable probabilities (around 50%) to the desired classes for the final samples, but these samples did not match the intended classes upon visual inspection. Scaling up the classifier gradients remedied this problem, and the class probabilities from the classifier increased to nearly 100%.
2022年谷歌提出Classifier-Free Guidance diffusion方案,可以规避上述问题,而且可以通过调节引导权重,控制生成图像的逼真性和多样性的平衡,DALL·E 2和Imagen等模型都是以它为基础进行训练和推理。
- 训练时,Classifier-Free Guidance需要训练两个模型,一个是无条件生成模型,另一个是条件生成模型。但这两个模型可以用同一个模型表示,训练时只需要以一定概率将条件置空即可。
- 推理时,最终结果可以由条件生成和无条件生成的线性外推获得,生成效果可以通过引导系数调节,控制生成样本的逼真性和多样性的平衡。


Efficient sampling
生成速度主要受step的影响,可以从多个方面提升生成速度:
- 跨step生成和结合,减少step次数,如DDIM方法
- 模型中前一个step的latent vector的重复利用,减少部分step中的部分计算量
- 具体算法上SDE solver(Stochastic Differential Equations),ODE solver(Ordinary Differential Equations),Knowledge Distillation等
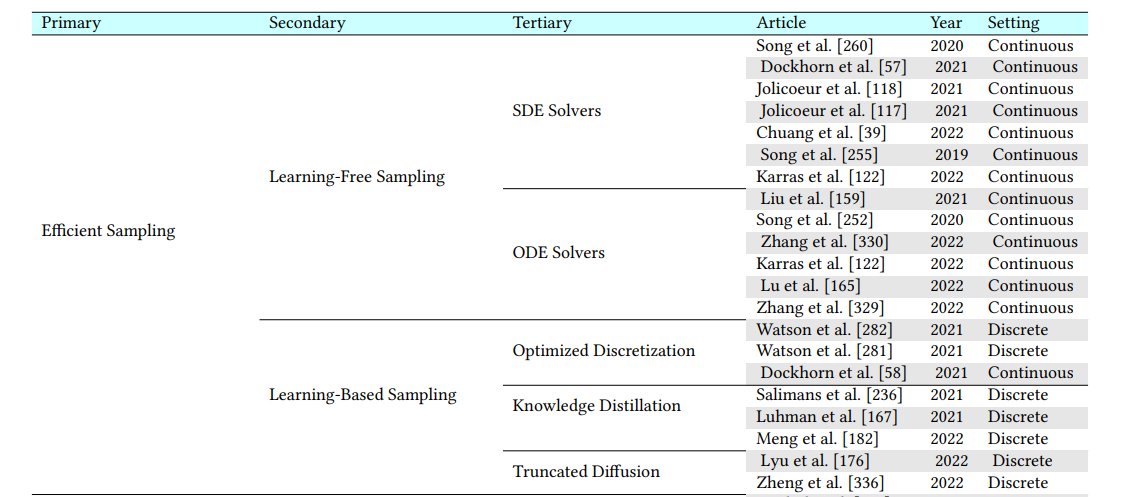
https://arxiv.org/pdf/2209.00796.pdf
Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models
One of the key components within diffusion models is the UNet for noise prediction. While several works have explored basic properties of the UNet decoder, its encoder largely remains unexplored....
Transformer-based Diffusion
Stable Diffusion
The Illustrated Stable Diffusion
Translations: Chinese, Vietnamese. (V2 Nov 2022: Updated images for more precise description of forward diffusion. A few more images in this version) AI image generation is the most recent AI capability blowing people’s minds (mine included). The ability to create striking visuals from text descriptions has a magical quality to it and points clearly to a shift in how humans create art. The release of Stable Diffusion is a clear milestone in this development because it made a high-performance model available to the masses (performance in terms of image quality, as well as speed and relatively low resource/memory requirements). After experimenting with AI image generation, you may start to wonder how it works. This is a gentle introduction to how Stable Diffusion works. Stable Diffusion is versatile in that it can be used in a number of different ways. Let’s focus at first on image generation from text only (text2img). The image above shows an example text input and the resulting generated image (The actual complete prompt is here). Aside from text to image, another main way of using it is by making it alter images (so inputs are text + image).
https://jalammar.github.io/illustrated-stable-diffusion/
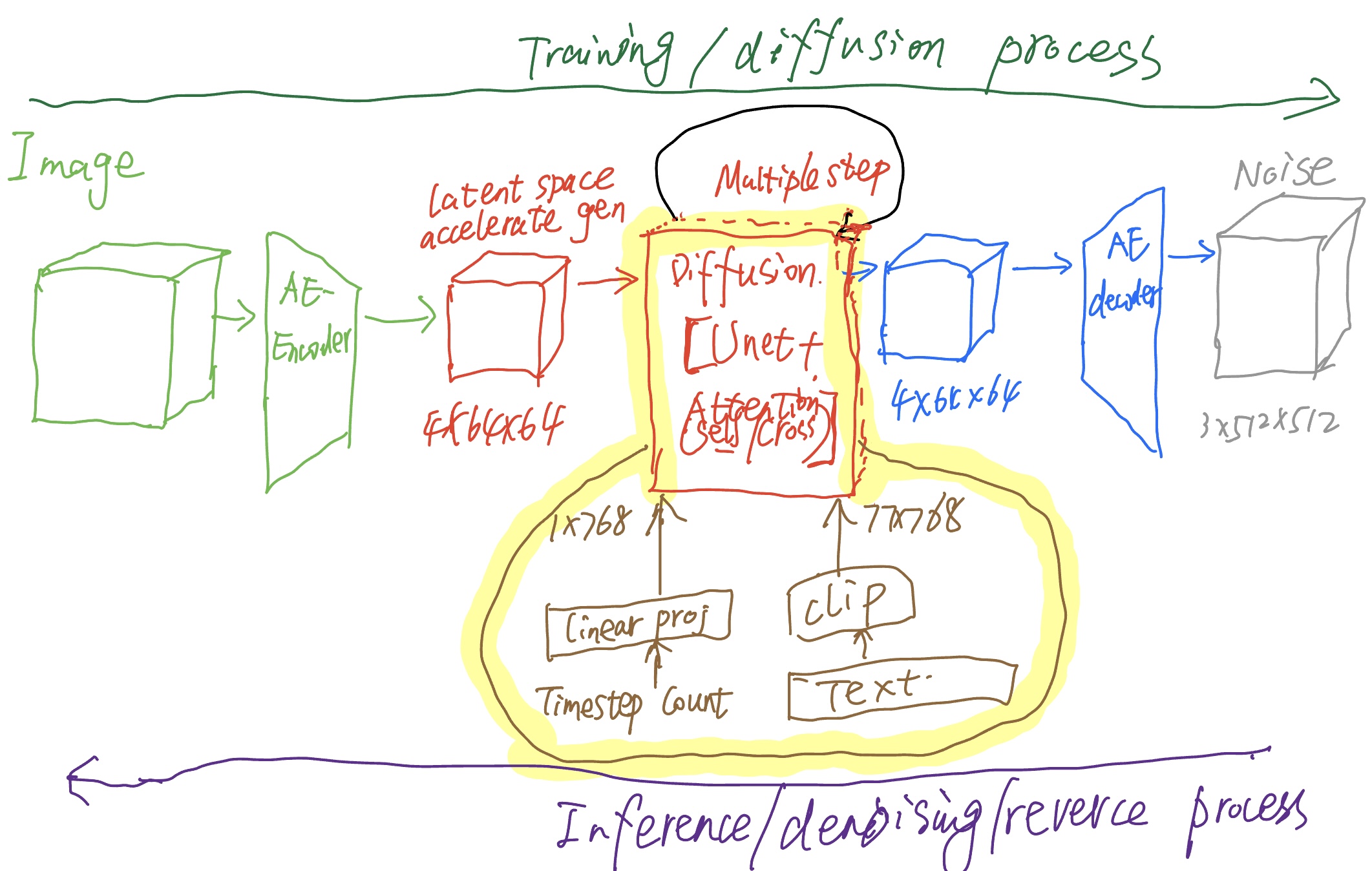
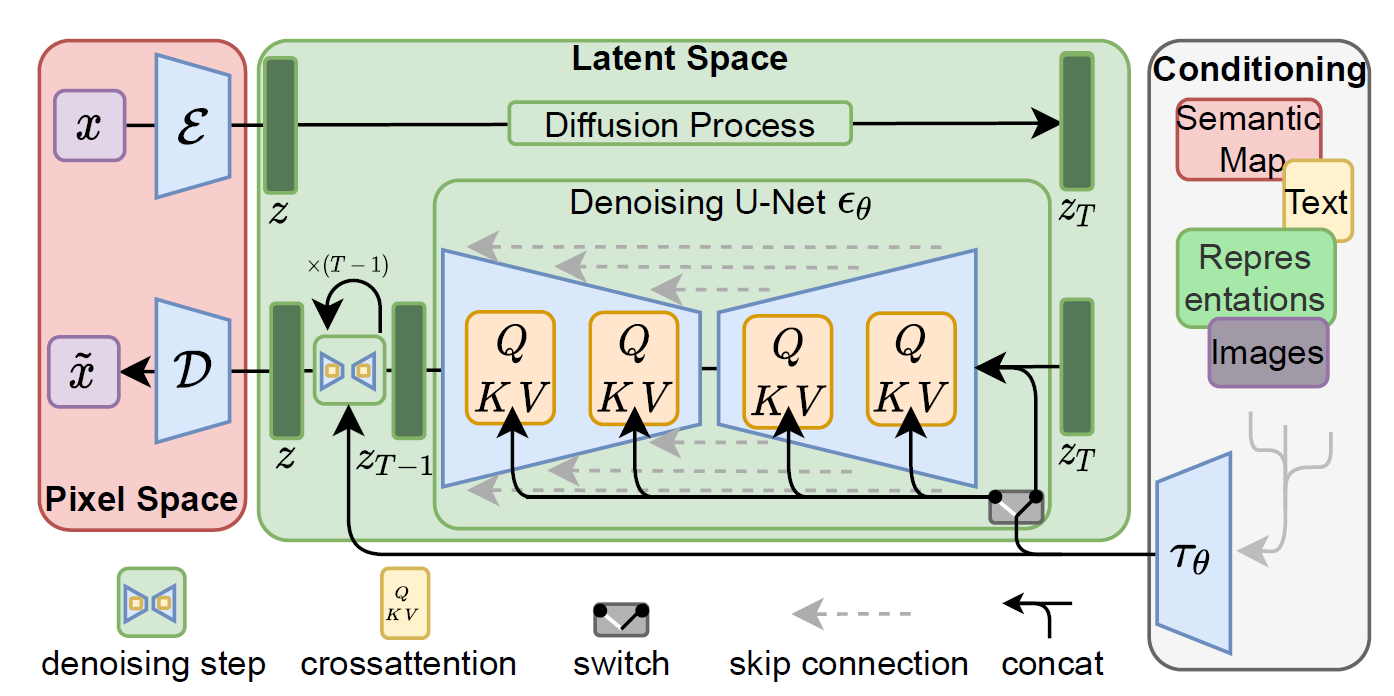
- 两大模块,autoencoder和diffusion model的结合
- autoencoder主要用于加速生成过程,通过在最开始把图像encoder到更低维的latent space,可加速diffusion生成过程,生成完之后再decoder回更高维的图像维度
- 通过diffusion的denoising过程,生成图像
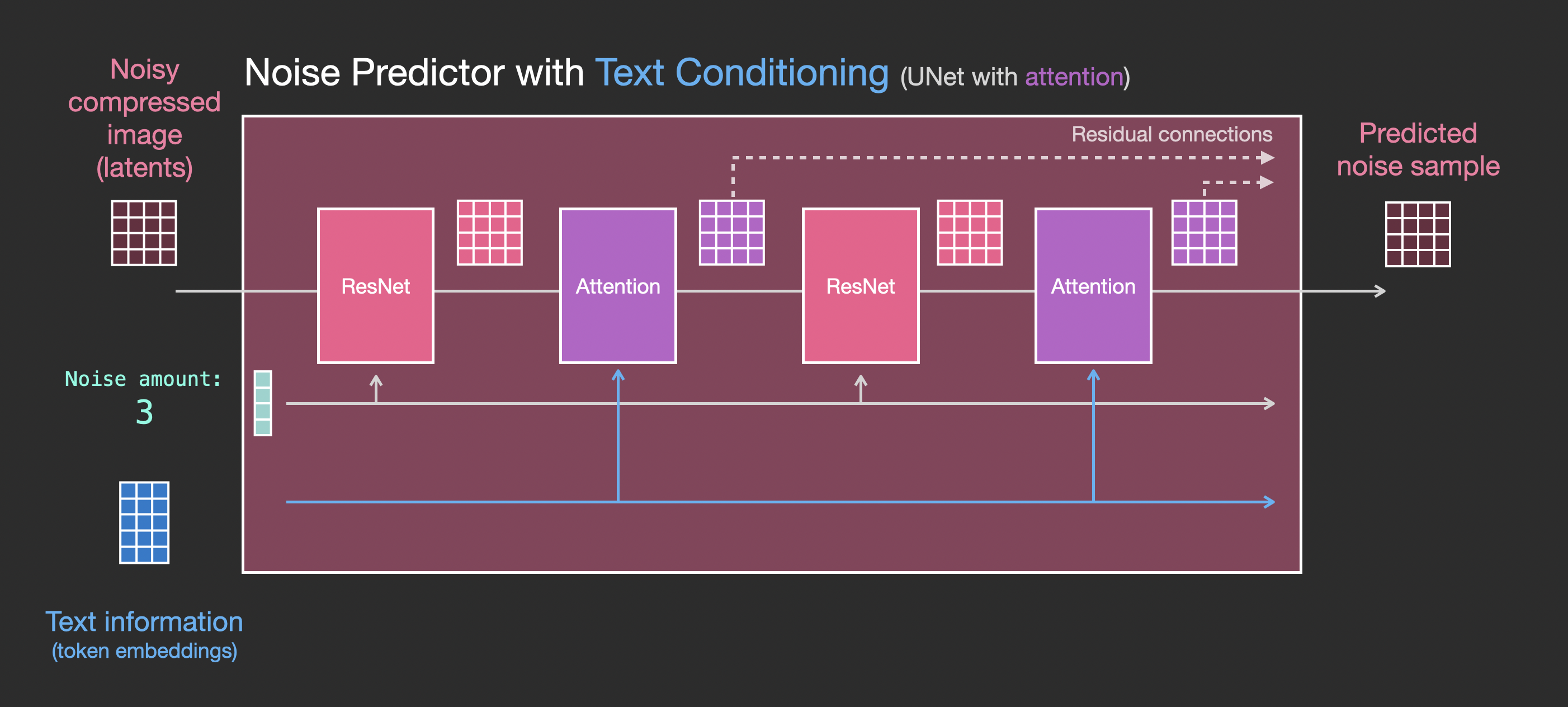
- diffusion model由unet融合attention构成,输入没有文本时,就是self-attention;
- 当输入包含文本时,即有condition时,根据文本生成;文本通过clip等LM encode之后,attention模块就是cross-attention
- 此外,diffusion model的输入还包含diffusion timestep的embedding vector

- 针对diffusion based image or video generation, 强调了curated or high quality training data的重要性
- 针对CLIP的研究也强调了high quality data and data augmentation的重要性
DALL.E 2
OpenAI DALL-E 2 是一种基于语言的人工智能图像生成器,可以根据文本提示创建高质量的图像和艺术作品。
CLIP+Diffusion
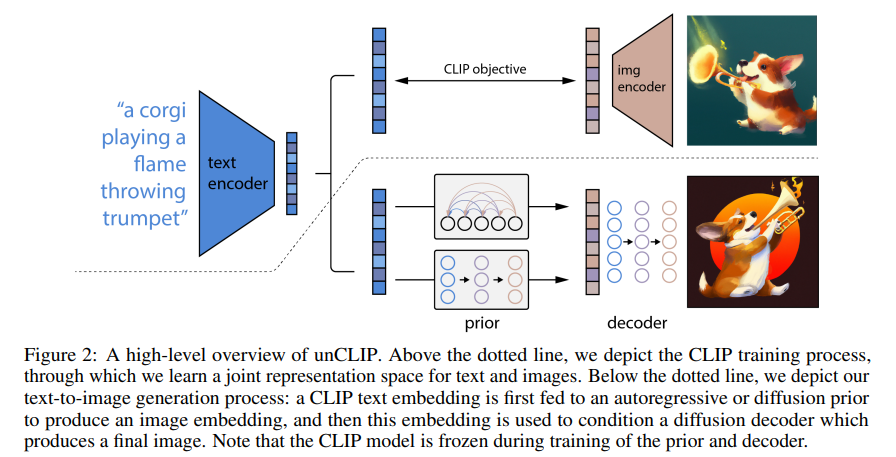
https://cdn.openai.com/papers/dall-e-2.pdf
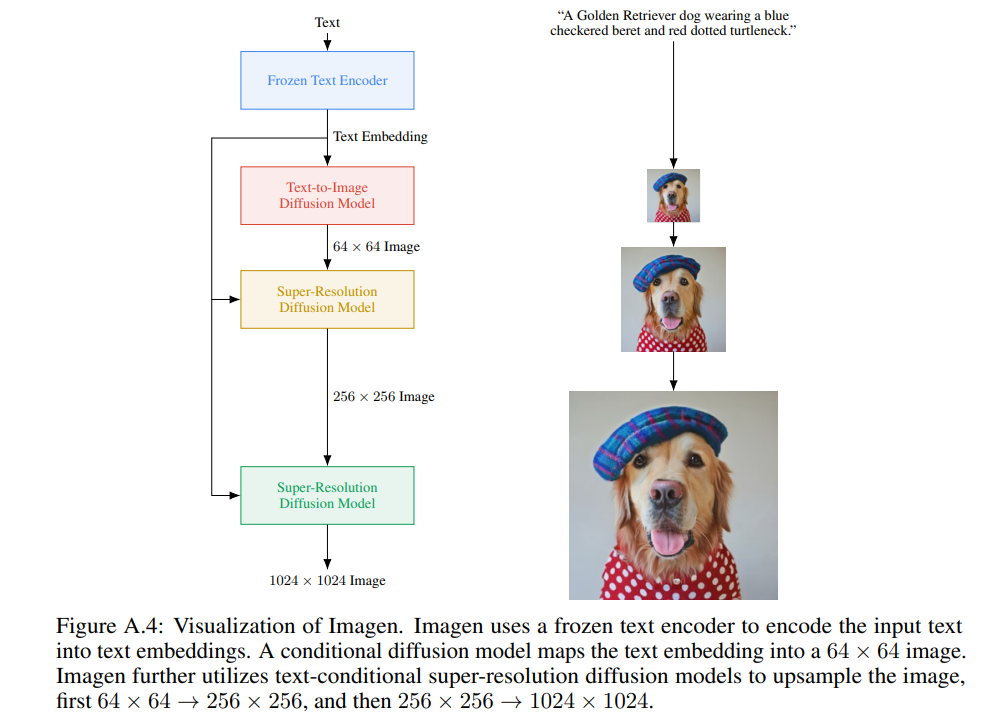
Imagen
Google Text-to-Image Diffusion Model
https://arxiv.org/pdf/2205.11487.pdf
Sora
Sora is a generalist model of visual data—it can generate videos and images spanning diverse durations, aspect ratios and resolutions, up to a full minute of high definition video.
- Turning visual data into patches
- Video compression network,We train a network that reduces the dimensionality of visual data.20 This network takes raw video as input and outputs a latent representation that is compressed both temporally and spatially.
- Spacetime latent patches,Given a compressed input video, we extract a sequence of spacetime patches which act as transformer tokens.
- Scaling transformers for video generation,Sora is a diffusion mode; given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches. Importantly, Sora is a diffusion transformer.
- Variable durations, resolutions, aspect ratios,Past approaches to image and video generation typically resize, crop or trim videos to a standard size—e.g., 4 second videos at 256x256 resolution. We find that instead training on data at its native size provides several benefits.
- Sampling flexibility
- Improved framing and composition
- Language understanding
- We apply the re-captioning technique introduced in DALL·E 3 to videos. We first train a highly descriptive captioner model and then use it to produce text captions for all videos in our training set. We find that training on highly descriptive video captions improves text fidelity as well as the overall quality of videos.
- we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model.
- Prompting with images and videos
- Video-to-video editing,we apply SDEdit to Sora. This technique enables Sora to transform the styles and environments of input videos zero-shot.
- Connecting videos
- Image generation capabilities
- Emerging simulation capabilities
- 3D consistency. Sora can generate videos with dynamic camera motion. As the camera shifts and rotates, people and scene elements move consistently through three-dimensional space.
- Long-range coherence and object permanence.
- Interacting with the world.
- Simulating digital worlds.
- Limitation:Sora currently exhibits numerous limitations as a simulator. For example, it does not accurately model the physics of many basic interactions, like glass shattering. Other interactions, like eating food, do not always yield correct changes in object state.

Video generation models as world simulators
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.

An Overview of Diffusion Models: Applications, Guided Generation,...
Diffusion models, a powerful and universal generative AI technology, have achieved tremendous success in computer vision, audio, reinforcement learning, and computational biology. In these...